- 저자
- 존 맥코믹
- 출판
- 에이콘출판
- 출판일
- 2013.05.31
0.
저렴하지만 훌륭한 신뢰성을 갖춘 복잡한 장치의 시대가 도래했다. 이에는 분명히 원인이 있다.
사실 컴퓨터는 스스로 판단이나 해석을 할 수 없으므로, 인간에게는 매우 간단해 보이는 문제도 인간이 이를 푸는 정확한 절차와 방법을 제공해야만 해결할 수 있다. 이를 알고리즘이라 하며 지금 여러분 눈앞에 있는 컴퓨터는 누군가 만들어놓은 알고리즘 덕분에 다양한 일처리를 하고 있는 셈이다.
페이지랭크(PageRank) :: 월드 와이드 웹과 같은 하이퍼링크 구조를 가지는 문서에 상대적 중요도에 따라 가중치를 부여하는 방법이다. 이 알고리즘은 서로간에 인용과 참조로 연결된 임의의 묶음에 적용할 수 있다.
페이지랭크는 스탠퍼드 대학교에 재학 중이던 래리 페이지와 세르게이 브린이 새로운 검색 엔진에 대한 연구 기획의 일부로 개발한 것이다. 이 기획은 1995년 시작되어, 1998년 구글이라 불리는 시범 서비스로 발전하였다. 페이지와 브린은 페이지랭크에 기반한 검색 기술을 바탕으로 구글 사를 설립하였다.
[위키백과] 페이지랭크[PageRank]
1. 시작하며: 컴퓨터를 움직이는 위대한 아이디어들
오늘날 컴퓨터 사용자들은 하루에도 몇 번씩이고 이와 같은 위대한 기능들을 사용한다. 그것이 어떤 기발한 아이디어에서 비롯됐는지 인식조차 못한 채 말이다.
알고리즘이란 문제를 푸는 데 필요한 단계의 순서를 명확히 명시하는 구체적인 계산법이다. 각 단계는 절대적으로 정확해야 하며 어떤 인간적 직관이나 추측도 요하지 않는다.
알고리즘의 또 다른 중요한 기능은 입력 내용에 상관없이 늘 작동한다는 점이다. 우리가 학교에서 배운 덧셈 알고리즘은 실제로 이런 특성을 지닌다. 더할 두 숫자에 관계없이 알고리즘은 결국 정확한 답을 생산한다. 예를 들어 좀 시간이 걸리더라도, 이 알고리즘을 이용해 천 자리 수도 더할 수 있다.
처치-튜링 명제(Church-Turing thesis) :: 계산가능한 함수에 대한 명제이다. 간단히 요약하면, 어떤 함수는 튜링 기계가 계산할 수 있으면, 그리고 그 때만 알고리듬으로 계산 가능하다 명제이다. 알론조 처치와 앨런 튜링의 이름을 따 지어졌다. 튜링 기계는 모든 범용 프로그래밍 언어로 번역될 수 있으므로, 이것은 어떤 컴퓨터에게든 충분한 시간과 메모리가 주어진다면 존재하는 모든 알고리즘의 결과를 출력할 수 있다는 명제와 동치이다.
처음 이 명제가 나왔을 때에는 "효과적으로 계산할 수 있는 (effectively computable) 함수"와 같이 비형식적인 표현을 사용했기 때문에 이 명제를 논리적으로 증명하는 것은 불가능했다. 이후 수학자들은 모호한 말 대신 계산가능한 함수를 사용한다.
실제로 증명되거나 반증된 적은 없으며, 영원히 증명할 수 없을 것이라고 주장하는 학자도 있다. 다만 현재까지 인간이 발명한 모든 종류의 계산법(양자컴퓨터를 포함하여)이 적절한 형태의 튜링 기계로 표현될 수 있음이 알려져 있다.
[위키백과] 처치-튜링 명제[Church-Turing thesis]
수학과 물리학 같은 일반 과학 분야에서 중요한 결과는 대개 하나의 공식으로 포착된다(유명한 예로 피타고라스 정리인 a2+b2 = c2이나 아인슈타인의 E = mc2이 있다). 이와는 대조적으로 컴퓨터과학에서 위대한 아이디어는 일반적으로 (물론 알고리즘을 이용해) 문제를 푸는 방법을 기술한다.
퀵 정렬(quick sort) :: 기준키를 기준으로 작거나 같은 값을 지닌 데이터는 앞으로, 큰 값을 지닌 데이터는 뒤로 가도록 하여 작은 값을 갖는 데이터와 큰 값을 갖는 데이터로 분리해가며 정렬하는 방법이다.
[네이버 지식백과] 퀵 정렬 (컴퓨터 개론, 2013.3.10., 한빛아카데미(주))
다익스트라 최단 경로 알고리즘 (Dijkstra’s shortest-path algorithm) :: 컴퓨터 과학에서, 데이크스트라 알고리즘(영어: Dijkstra algorithm)은 어떤 변도 음수 가중치를 갖지 않는 유향 그래프에서 주어진 출발점과 도착점 사이의 최단 경로 문제를 푸는 알고리즘이다. 이름은 네덜란드의 컴퓨터과학자 에츠허르 데이크스트라의 이름에서 유래했다. 예컨대 어떤 그래프에서, 꼭짓점들이 각각 도시를 나타내고, 변들이 도시 사이를 연결하는 도로의 길이를 나타낸다면, 데이크스트라 알고리즘을 통하여 두 도시 사이의 최단 경로를 찾을 수 있다.
[위키백과] 데이크스트라 알고리즘
사실 컴퓨터과학에서 가장 아름다운 아이디어들은 상당수가 매우 추상적이며, 소프트웨어나 하드웨어 분야 어느 쪽에도 속하지 않는다.
훨씬 더 어려운 문제인 ‘위대함’의 정의를 내리기보다는, 거꾸로 ‘위대한 알고리즘’의 잠정적 후보들을 하나씩 배제시키는 기준들을 열거하는 방법을 썼다.
“아름다움은 가장 중요한 시험대다. 추한 모습의 수학이 영원히 자리잡을 곳은 이 세상 어디에도 없다.”
- 하디(영국 수학자),《어느 수학자의 변명》
21세기의 첫 10년
부지불식간에 압축 기술은 훨씬 더 자주 이용된다. 사용자가 의식조차 못하지만 다운로드 또는 업로드되는 파일은 대역폭을 절약하기 위해 압축되고, 데이터 센터에서는 대개 고객의 데이터를 압축해 비용을 줄인다. 이메일 제공 업체가 고객에게 제공하는 5GB공간보다 제공 업체가 보유한 저장 장치의 5GB에는 훨씬 많은 데이터가 저장된다.
우리 시대에서 가장 편재하고 불가해한 블랙박스인 컴퓨터, 즉 여러분 앞에 놓인 천재의 진가를 알아보게 될 것이다.
2. 검색엔진 인덱싱: 세상에서 가장 큰 건초 더미에서 바늘 찾기
우리 대부분은 하루에도 몇 번씩 검색 쿼리(query)를 던지지만 이 탁월한 툴의 작동 원리를 그다지 궁금해 하지 않는다. 막대한 정보의 양도, 빠른 속도로 나오는 훌륭한 결과도 이제는 늘 있는 일이라, 몇 초 안에 질문에 대한 답을 얻지 못하면 짜증이 밀려온다. 우리는 모든 성공적인 웹 검색이 월드와이드웹(World Wide Web)이라는 세상에서 가장 큰 건초 더미에서 바늘을 찾는 작업이라는 점을 자주 잊는다.
매칭과 랭킹
매칭 단계는 ‘어떤 웹사이트가 내 쿼리에 부합하는가?’라는 질문에 답한다.
좋은 검색엔진은 최선의 검색결과를 선별할 뿐 아니라 (가장 적합한 페이지를 우선 보여 주고, 그 다음으로 적합한 페이지를 보여 주는 식으로) 가장 유용한 순서에 따라 결과를 보여 준다.
가장 좋은 소수의 검색결과를 적절한 순서로 선별하는 작업을 ‘랭킹’이라 부른다.

구글이 검색 산업의 강자로 부상하게 된 것은 랭킹 알고리즘 덕분이라 여겨진다.
웹 검색기법을 최초로 상용 도입한 기업은 (1994년 출범한) 인포시크(Infoseek)와 라이코스(Lycos), 1995년에 검색엔진을 출범시킨 알타비스타(AltaVista)였다.
오래된 평범한 인덱싱
인덱싱이란 발상은 글쓰기만큼이나 오래됐다. 5,000년 전에 지어진 바빌론 신전 도서관에서도 주제에 따라 설형 문자판을 분류해 놓았던 것을 볼 수 있다.
웹 검색엔진용 인덱스는 책의 인덱스와 같은 방식으로 작동한다. 이 책의 ‘페이지’는 이제 월드와이드웹상의 웹페이지고 검색엔진은 웹에 있는 모든 개별 웹페이지에 저마다 다른 페이지 번호를 할당한다(물론 최종 집계에서 수억 개에 달하는 많은 페이지가 있지만 컴퓨터는 큰 수를 다루는 데 탁월하다).

컴퓨터는 우선 모든 페이지에 등장하는 모든 단어의 목록을 만들고 이 목록을 알파벳 순으로 정리해 세 개 웹페이지의 인덱스를 구축할 수 있다. 그 다음에 컴퓨터는 단어별로 페이지들을 빠르게 살펴본다. 각 단어에 대해 컴퓨터는 단어 목록에서 대응하는 단어 옆에 현재 페이지 번호를 적는다.
구문 쿼리는 페이지 어딘가에 있는 어떤 단어를 막 찾는 것이 아닌 정확한 구문을 검색하는 쿼리이며, 대부분 검색엔진에서 인용 부호를 이용해 입력한다.
예컨대 "cat sat"이라는 쿼리는 cat sat이라는 쿼리와는 전혀 의미가 다르다. cat sat이라는 쿼리는 ‘cat’과 ‘sat’이란 두 단어를 위치와 순서에 상관없이 포함한 페이지를 찾는다. 반면 "cat sat"이 구문은 ‘cat’ 바로 다음에 ‘sat’이 뒤따르는 경우를 포함하는 페이지를 찾는다.
단어 위치 트릭
단어 위치 트릭은 인덱스가 페이지 번호뿐 아니라 페이지 안의 위치도 저장해야 한다는 아이디어에서 출발한다.

"cat sat"이란 구문에 대한 검색결과를 원래 웹페이지가 아닌 인덱스 정보(‘cat’에 대해선 1-2, 3-2, ‘sat’에 대해선 1-3, 3-7)만 보고 찾았다는 사실에 주목하라.
요컨대 인덱스에 페이지 내 단어 위치를 포함하면 우리는 수많은 웹페이지를 읽는 대신 인덱스에 있는 두 줄만 보고 구문 쿼리 결과를 찾을 수 있다. 이렇게 간단한 단어 위치 트릭이 검색엔진을 작동하는 열쇠가 된다!
주목하라. 어떤 웹페이지의 실제 내용도 읽을 필요가 없었다. 대신 인덱스에서 두 항목만 참고했을 뿐이다.
NEAR 키워드 검색 :: cat NEAR dog이라는 쿼리로 ‘cat’이란 단어가 ‘dog’이란 단어로부터 일정 단어 안에 있는 페이지를 찾는 검색
NEAR 쿼리가 검색엔진 이용자에게는 별로 중요하지 않다는 점이 밝혀졌다. 거의 아무도 NEAR 쿼리를 이용하지 않고 대부분 검색엔진은 이를 지원조차 하지 않는다. 그럼에도 NEAR 쿼리를 수행하는 능력은 실제 검색엔진에는 중요하다. 이는 검색엔진 자체가 이면에서 NEAR 쿼리를 끊임없이 수행하기 때문이다.
랭킹과 접근성
두 번째 단계인 ‘랭킹’은 고품질의 검색엔진에 절대적으로 필수다. 이는 사용자에 보여 줄 소수의 상위 검색결과를 선별하는 단계다.
페이지의 ‘순위(rank)’는 실제로 무엇에 달려 있는가? 진짜 질문은 ‘이 페이지가 쿼리에 부합하는가?’가 아니라 ‘이 페이지가 쿼리에 적합한가?’이다.
쿼리단어가 서로 가까이 있는 페이지가 그렇지 않은 페이지보다 더 적합할 가능성이 높다.
컴퓨터는 이 쿼리의 주제를 실제로 ‘이해하지’ 못하지만 더 적합한 결과라고 추측할 수 있다.
요컨대 인간은NEAR 쿼리를 많이 쓰지 않지만 검색엔진은 랭킹을 향상시키고자 근접성에 관한 정보를 계속 이용한다.
메타워드 트릭
웹페이지는 웹브라우저가 이를 잘 짜인 형태로 보여 주는 (흔히 HTML과 같은) 특별한 언어로 작성되며, 표제, 제목, 링크, 이미지 등에 대한 서식 작성 명령은 메타워드라는 특수한 언어를 이용해 작성한다. 예를 들어, 웹페이지의 제목을 시작하는 데 이용하는 메타워드는 <titleStart>이고 제목을 끝내는 메타워드는 <titleEnd>이다. 이와 유사하게 웹페이지의 본문은 <bodyStart>로 시작하고 <bodyEnd>로 끝난다.

HTML에선 메타워드를 태그tag라 부르며, HTML에서 제목의 시작과 끝에 해당하는 태그는 <title>과 </title>이다.

메타워드 트릭은 검색엔진이 정확한 결과와 고품질의 랭킹을 내는 데 결정적인 역할을 한다. 잠시 검색엔진이 IN이란 핵심어를 이용한 특수 유형의 쿼리를 지원한다고 가정해 보자. 그래서 boat IN TITLE같은 쿼리는 웹페이지의 제목에 ‘boat’란 단어가 있는 페이지에 해당하는 검색결과만 출력하고 giraffe IN BODY는 ‘giraffe’가 본문에 있는 페이지만 찾는다.
검색엔진은 여러분이 쿼리 단어가 제목이나 문서의 어느 특정 부분에 있어야만 한다고 명시할 수 있는 ‘상세 검색(advanced search)’이란 검색 옵션을 클릭하면 같은 효과를 달성할 수 있다. 구글에서 intitle:이란 키워드를 이용해 제목 검색을 할 수 있다. 구글 쿼리 intitle:boat는 제목에 ‘boat’를 포함한 페이지를 찾는다.

유사한 기법으로 하이퍼링크, 이미지, 설명 등 웹페이지의 다양한 부분을 검색할 수 있다. 검색엔진은 원래 웹페이지로 돌아가 검색할 필요 없이, 적은 수의 인덱스 항목만 참고해 쿼리에 답할 수 있다. 각 인덱스 항목을 한번만 검색해도 된다는 점도 중요하다.
검색엔진의 성공여부를 판가름하는 이 랭킹은 웹페이지 구조를 얼마나 잘 활용하느냐에 따라 개선될 수 있다. 예를 들어 제목에 ‘개’가 있는 페이지는 본문에만 ‘개’를 언급한 페이지보다 개에 관한 정보를 더 많이 담고 있을 가능성이 크다. 그래서 사용자는 ‘개’라는 단순한 쿼리를 입력할 때 (사용자가 명시적으로 요청하지 않더라도) 검색엔진은 내부적으로 ‘개 IN TITLE’ 검색을 수행해서 우연히 개를 언급한 페이지가 아닌 개에 관해 다룰 가능성이 가장 큰 페이지를 찾는다.
인덱싱과 매칭 트릭이 전부는 아니다
알타비스타가 (다른 검색엔진은 실패했던) 전체 웹에서 딱 들어맞는 결과를 찾는 데 성공한 이유는 메타워드 트릭 덕분이었다는 것을 1999년 알타비스타가 제출한 <인덱스 제한 검색(Constrained Searching of an Index)>이라는 미국 특허에서 볼 수 있다.
효율적 매칭은 효과적 검색엔진이 되는 데 딱 절반 정도의 역할을 할 뿐이다. 나머지 과제는 적절하게 매칭된 페이지의 순위를 매기는 일, 즉 랭킹이다. 새로운 유형의 랭킹 알고리즘은 알타비스타를 몰락시키고 구글을 웹 검색 세계의 중심으로 올려 놓기에 충분했다.
3. 페이지랭크: 구글을 출범시킨 기술
구글이 엘리트 지위를 얻을 수 있었던 것은 ‘극도로 적합한 결과를 출력하는 불가사의한 재주’ 덕이었다.
가장 중요한 요인 중 하나는 구글이 검색결과의 순위를 매기는 데 이용한 혁신적 알고리즘인 페이지랭크(PageRank)다.
페이지와 브린은 이 알고리즘을 1998년 <대규모 하이퍼텍스트 웹검색 엔진의 해부(The Anatomy of a Large-scale Hypertextual Web Search Engine)>라는 학회 논문으로 발표했다. 논문 제목에서 알 수 있듯 이 논문은 페이지랭크의 기술보다 훨씬 많은 내용, 즉 1998년 당시 구글 시스템을 완벽하게 설명하고 있다.
하이퍼링크 트릭
1945년 미국 엔지니어 바네바 부시는 <우리가 생각하는 대로(As We May Think)>라는, 시대를 앞선 전방위적인 글에서 여러 가지 새로운 잠재 기술에 대해 언급했다. 글에서 메멕스(Memex)라는 기계는, 문서를 저장하고 자동으로 인덱싱할 뿐 아니라 그 이상의 작업을 한다. 이는 어떤 항목이 다른 항목을 즉시 그리고 자동으로 찾아내는 원인이 되는 연관 인덱싱(associative indexing), 달리 말해 하이퍼링크의 기본 형식을 가능하게 하는 기술이었다.

각 페이지에 있는 인커밍 링크(incoming link)의 수(이 경우 어니에 하나, 버트에 세 개)에 따라 레시피 순위를 매기는 방법으로 접근했다.
추천보다 혹평의 내용이 있는 링크라도 하이퍼링크 트릭은 그 페이지에 마땅한 만큼보다 더 높은 순위를 줄 수 있다.
권위 트릭
컴퓨터과학 책의 저자가 추천한 레시피보다는 유명한 요리가 추천한 레시피를 선택하는 편이 낫다. 이 기본 원리를 권위 트릭(authority trick)이라고 부른다. 높은 ‘권위’가 있는 페이지에서 온 링크는 낮은 권위가 있는 페이지의 링크보다 더 높은 순위라는 결과를 낳아야 한다.
하이퍼링크 트릭과 권위 트릭을 결합하자. 모든 페이지는 1점의 권위 점수로 시작한다. 그러나 한 페이지에 인커밍 링크가 있다면 이를 지칭하는 모든 페이지의 권위를 추가해서 권위를 계산한다. 다시 말해 X와 Y라는 페이지가 Z라는 페이지에 링크돼 있다면 Z의 권위는 X와 Y의 권위를 더한 권위와 같다.

무작위 서퍼 트릭
사이클은 하이퍼링크를 클릭하다가 출발점으로 되돌아오는 경우를 말한다.

무작위 서퍼 트릭(random surfer trick)으로 사이클의 문제를 해결할 수 있다. 무작위로 선택한 하나의 웹페이지에서 출발한다. 그 다음, 이 페이지에 있는 모든 하이퍼링크를 검토하고 이중 하나를 무작위로 골라 클릭한다. 이것을 반복하는 과정을 지속한다. 이는 하이퍼링크와 권위 트릭의 순기능을 결합했지만 하이퍼링크 사이클이 있을 때도 작동한다.

무작위 서퍼 시뮬레이션에서 계산한 백분율은 정확히 페이지의 권위를 측정하는 데 필요한 수치다. 서퍼 권위 점수는 웹페이지의 중요성 순위를 매기는 앞선 두 트릭을 모두 포함한다.
우선 하이퍼링크 트릭이 있었다. 여기서 주요 개념은 많은 인커밍 링크가 있는 페이지가 더 높은 순위를 받아야 한다는 점이었다. 이는 무작위 서퍼 모델에서도 그렇다. 많은 인커밍 링크를 가진 페이지를 많이 방문할 가능성이 크기 때문이다.
둘째로 권위 트릭이 있었다. 핵심 개념은 높은 권위를 가진 페이지로부터의 인커밍 링크는 낮은 권위를 가진 페이지로부터의 인커밍 링크보다 페이지의 순위를 높인다는 내용이었다. 이번에도 무작위 서퍼 모델은 이를 감안한다. 인기 있는 페이지로부터의 인커밍 링크는 인기없는 페이지로부터의 링크보다 더 따라갈 기회가 많기 때문이다.
무작위 서퍼 모델이 하이퍼링크 트릭과 권위 트릭을 동시에 포괄한다는 사실, 즉 각 페이지에 있는 인커밍 링크의 질과 양을 모두 계산한다는 것을 주목하라.
무작위 서퍼 트릭은 사이클이 있어도 적절한 점수를 계산하는 데 전혀 문제가 없다.
실제 페이지랭크
구글의 두 공동 창업자는 (지금은 유명한) 1998년 컨퍼런스 논문인 <대규모 하이퍼텍스트 웹 검색엔진의 해부>에서 무작위 서퍼 트릭을 설명했다.
하이퍼링크가 정당한 권위를 부여한다는 가정이 때론 의문시된다. 우리는 하이퍼링크가 추천보다 혹평을 반영할 수 있지만 이는 실제로 중요한 문제가 될 가능성이 낮다고 이미 배웠다. 이보다 훨씬 더 심각한 문제는 사람들이 자기 웹페이지의 순위를 인위적으로 부풀리고자 하이퍼링크 트릭을 남용할 수 있다는 점이다.
자동화 기술을 이용해 특정 홈페이지로 링크를 가진 매우 많은 웹페이지를 제작하기란 비교적 쉽다. 그러므로 검색엔진이 여기서 기술한 그대로 페이지 랭크 권위를 계산하면 수천 배 높은 점수를 부당하게 받게 되고 높은 순위에 오르게 된다.
검색엔진은 이런 종류의 남용을 웹 스팸(web spam)이라고 부른다.
검색엔진은 웹 스패머에 맞서 군비 경쟁(arms race)을 하게 되고 실질적인 순위를 출력하고자 알고리즘을 끊임없이 개선하려 한다. 이런 종류의 알고리즘을 대개 링크 기반 랭킹 알고리즘(link-based ranking algorithms)이라 부른다.
또 다른 복잡한 요인은 페이지랭크 계산의 효율성과 연관된다. 이 책에서는 서퍼 권위 점수를 무작위 시뮬레이션을 돌려 계산했지만 전체 웹을 대상으로 이렇게 시뮬레이션을 구동하는 것은 너무 오래 걸려 실제로 사용할 수 없을 것이다. 그래서 검색엔진은 무작위 서퍼를 시뮬레이션해 페이지랭크 값을 계산하지 않는다. 대신 무작위 서퍼 시뮬레이션과 같은 값을 제시하면서도 훨씬 적은 계산 비용이 드는 수학 기법을 이용한다.
1998년에 공개된 구글 설명에서조차 구글의 두 공동 창업자는 검색결과 랭킹에 기여하는 여러 다른 특징(feature)을 언급했다. 예상했겠지만, 여기서 기술이 시작됐다. 이 글을 쓰고 있는 현재, 구글의 웹사이트에서는 페이지 중요도 평가에 ‘200개 이상의 신호를 이용’한다고 명시한다.
오늘날 검색엔진이 매우 복잡해지기는 했지만, ‘권위 있는 페이지는 하이퍼링크를 통해 다른 페이지에 권위를 부여한다.’는 페이지랭크의 핵심 아이디어는 여전히 유효하다. 이는 불과 몇 년 사이에 소규모 회사였던 구글이 알타비스타를 밀어내고 검색왕 자리에 오르는 데 도움을 준 아이디어였다. 페이지랭크의 핵심 알고리즘이 없었다면 대부분 웹 검색 쿼리는 수천 개의 ‘부합하지만 부적합한’ 웹페이지의 바다에 빠졌을 것이다.
4. 공개 키 암호화: 공개 엽서에 비밀을 적어 아무도 모르게 보내는 방법
공개 키 암호화(public cryptography) :: 공개키 암호화(PKC)는 참가자들이 자신의 신원을 다른 사람에게 전자상으로 확인시켜 줄 수 있게 해주는 기술이다. 수천 년간 서명은 자신의 신원을 예술품에 표기하는 데 사용되었으나 화폐와 계약의 개념이 전 세계로 퍼져나감에 따라 예술적인 목적이 아닌 일상 계약에서의 신원 증명 목적으로 사용되었다. 하지만 서명은 전자 보안에서 사용자의 신원을 증명하는 데 비실용적이었다.
각국 정부는 공개키 암호화의 잠재성을 깨닫기 시작했으며 자신들만의 기술을 유지하려고 노력했다. 1970년대 초반 제임스 엘리스(1924~1997), 클리포드 콕스(1950년 출생), 말콤 윌리엄슨(1950년 출생)은 영국 정부를 위한 암호화 방식을 연구하던 중 공개키 암호화 시스템을 개발하였다. 1997년 새로운 영국 정부의 ‘개방(openness)’ 정책하에 영국은 24년 전에 개발한 공개키 암호화(PKC)를 전 세계에 공개했다. 수많은 교재가 공개키 암호화를 주제로 집필되었지만 공개키 암호화의 발견이 스탠포드 대학교의 마틴 헬맨, 랄프 머클, 위트필드 디피에 의해 이루어졌다고 기술하였다.
공개키 암호화에 대하여 자세하게 설명하려면 내용이 복잡해질 수 있으니 근본적인 핵심 내용만 다루고자 한다. 공개키 암호화의 요점은 두 개의 컴퓨터나 사람이 완벽한 프라이버시를 보장받으면서 통신하는 데 있다. 공개키 암호화 코드의 해킹이 가능하다고 알려져 있는 방법은 아직까지 존재하지 않는다. 공개키 암호화 처리 과정을 위한 수학적 공식 개발에 누가 기여했는지 현 시점에서 따지는 것은 부적절하다. 많은 사람이 온라인 거래 시 공개키 암호화를 통해 안전을 보장받고 있다.
[네이버 지식백과] 공개키 암호화 (죽기 전에 꼭 알아야 할 세상을 바꾼 발명품 1001, 2010.1.20., 마로니에북스)
인터넷상의 어떤 메시지든 라우터(router)라 불리는 수많은 컴퓨터를 거쳐 여행하기에 이 라우터에 접속하면 누구든지 메시지 내용을 볼 수 있다. 그러므로 사용자의 컴퓨터를 떠나 인터넷에 들어가는 모든 개별 데이터는 엽서에 작성된 셈이다.
엽서에 메시지를 쓰기 전에 이를 암호화하는 비밀 코드를 쓰면 어떨까? 실제로 엽서를 받을 사람을 이미 아는 경우엔 효과가 있다. 과거 어느 시점에 어떤 비밀 코드를 사용할지 합의했을 수 있기 때문이다. 진짜 문제는 엽서를 누가 받게 될지 모르는 경우다. 여러분이 이 엽서에 비밀 코드를 쓴다면 우체부뿐 아니라 수신자도 메시지를 읽을 수 없다! 공개 키 암호화의 진정한 힘은 (사용할 코드에 비밀스럽게 합의할 기회가 없었음에도) 수신자만 해독할 수 있는 비밀 코드를 이용할 수 있다는 데 있다.
공유 비밀로 암호화

공유 비밀을 대개 ‘키(key)’라 부른다. 비트 수의 30%를 계산하면 키의 근사 자릿수를 알 수 있다. 그렇다면 128의 30%는 약 38이므로 우리는 128비트 암호화는 38자리 숫자 키를 이용한다는 사실을 알게 된다. 38자리 숫자는 매우 큰 수이고 현존하는 어떤 컴퓨터도 이 모든 가능성을 시도하는 데 수십억 년이 걸리므로, 38자리 공유 비밀은 매우 안전하다고 할 수 있다.
오늘날 암호화 기법은 ‘블록 암호(block cipher)’라는 변형된 덧셈 트릭을 이용한다.
우선 긴 메시지를 통상 10~15자로 이뤄진 고정된 크기의 작은 ‘블록’으로 쪼갠다. 그 다음, 그냥 메시지 한 블록과 키를 더하는 대신 각 블록을 덧셈과 유사하지만 메시지와 키를 더 공격적으로 섞는 고정된 규칙에 따라 수 차례 변형한다. 예를 들어 ‘키의 앞 절반을 블록의 뒤 절반에 더하고 결과를 뒤집은 다음 키의 나머지 절반을 블록의 마지막 절반에 더하라.’ 같은 규칙을 말할 수 있다. 물론 실제 규칙은 이보다 훨씬 복잡하다. 오늘날 블록 암호는 주로 10‘차례’ 혹은 그 이상 작업을 한다.
가장 많이 쓰는 블록 암호는 고급 암호 표준(Advanced Encryption Standard(AES))이다. AES는 다양한 설정으로 이용할 수 있지만 일반적으로는 16자짜리 블록을 128비트 키와 함께 이용해 10차례의 혼합 계산을 하는 방식으로 사용한다.
공유 비밀을 공개적으로 설정하기
디피-헬먼 키 교환(Diffie-Hellman key exchange)이라 부른다.
디피-헬먼 키 교환(Diffie-Hellman key exchange) :: 디피-헬만 키 교환(Diffie–Hellman key exchange)은 암호 키를 교환하는 하나의 방법으로, 두 사람이 암호화되지 않은 통신망을 통해 공통의 비밀 키를 공유할 수 있도록 한다. 휫필드 디피와 마틴 헬만이 1976년에 발표하였다.
디피-헬만 키 교환은 기초적인 암호학적 통신 방법을 수립하였으며, 이후 1977년 공개 키 암호 방식인 RSA 암호가 제안되었다.
[위키백과] 디피-헬먼 키 교환[Diffie-Hellman key exchange]
페인트 혼합 트릭
디피-헬먼 키 교환(Diffie-Hellman key exchange)을 설명하기 위한 예제로 이를 페인트 혼합 트릭(paint-mixing trick)이라 부르겠다.
단계 1. 당신과 아놀드가 각각 ‘개인 색’을 고른다.
단계 2. 당신과 아놀드 중 한 명은 우리가 ‘공개 색’이라고 부를 새로운 색을 공개적으로 발표한다.
단계 3. 당신과 아놀드는 각각 개인 색 한 통과 공개 색 한 통을 섞어 혼합색을 만든다. 이는 당신의 ‘공개-개인 혼합색’을 생산한다.

단계 4.아놀드의 공개-개인 혼합색 통 하나를 골라 당신의 사적 공간으로 가져가서 여기에 당신의 개인 색 한 통을 더하라. 아놀드도 당신의 공개-개인 혼합색 하나를 그의 사적 공간으로 가져가 그의 개인 색 한 통을 이에 더한다.

숫자로 하는 페인트 혼합 트릭
일방향 행위(one-way action)란 수행을 할 수는 있지만 원상태로 되돌릴 수는 없는 행위를 뜻한다.
단계 1. 당신과 아놀드는 각자 ‘개인 색’ 대신 ‘개인 수’를 고른다.
단계 2. 당신과 아놀드 중 한 명이 (페인트 혼합 트릭에서 공개 색 대신) ‘공개 수’를 발표한다.
단계 3. 당신의 개인 수(4)와 공개 수(7)를 곱해 ‘공개-개인 수’ 28을 만든다.

단계 4. 당신은 아놀드의 공개-개인 수인 42에 당신의 개인 수인 4를 곱해 168이라는 공유 비밀 수를 만든다.

아놀드와 당신이 동일한 공유 비밀 색을 만들 수 있었던 이유는 당신이 아놀드가 고른 것과 동일한 세 가지 색을 섞었기 때문이었다. 단지 섞는 순서가 달랐을 뿐이다.
페인트 혼합 트릭의 실제
컴퓨터가 실제로 이를 행할 때 혼합 계산은 이산 누승법(discrete exponentiation)이라고 부르고 원상태로 돌리는 계산은 이산 로그(discrete logarithm)라 부른다. 그리고 컴퓨터가 이산 로그를 효율적으로 계산할 방법이 없기에 이산 누승법은 일방향 행위의 종류가 된다.
중요한 첫 번째 수학 개념은 나머지 연산(modular arithmetic)이라고도 불리는 시계 연산(clock arithmetic)이다.

두 번째 수학 개념은 거듭제곱 표기법이다.

단계 1. 당신과 아놀드는 각자 개인 수를 선택한다.
단계 2. 당신과 아놀드는 두 공개 수를 공개적으로 합의한다. 하나는 시계 크기(이 예에서는 11)이고 또 다른 하나는 기저수(base)(이 예에서는 2)다.
단계 3. 당신과 아놀드는 각자 거듭제곱 표기법과 시계 연산을 이용해 각자의 개인 수와 공개 수를 혼합해 공개-개인 수(PPN)를 만든다.
PPN = 기저수개인 수 (시계 크기)

단계 4. 당신과 아놀드는 각자 상대방의 공개-개인 수를 가져가 이를 각자의 개인 수와 섞는다.
공유 비밀 = 상대방의 PPN개인 수 (시계 크기)

공개 키 암호화의 실제
여기서 기술한 방법을 1976년 이 알고리즘을 처음으로 발표한 휫필드 디피와 마틴 헬먼의 이름을 따 디피-헬먼 키 교환 프로토콜이라 부른다. (‘http:’ 대신 ‘https:’로 시작하는) 보안된 웹사이트를 방문할 때마다 방문자의 컴퓨터와 이것이 통신하는 웹 서버는 디피-헬먼 프로토콜 또는 이와 비슷한 방식으로 작동하는 여러 대안 중 하나를 이용해 공유비밀을 제작한다. 그리고 일단 이 공유 비밀을 설정하면 두 컴퓨터는 앞서 설명한 덧셈 트릭의 변형을 이용해 모든 통신을 암호화한다.
작은 공개 시계 크기를 선택한다면 가능한 개인 숫자의 수도 줄어든다(시계 크기보다 작은 개인 수를 이용할 수밖에 없기 때문이다). 그리고 이는 다른 사람이 컴퓨터를 써서 모든 가능한 개인 수를 대입해 여러분의 공개-개인 수를 만든 수를 찾아낼 수도 있다는 뜻이다.
디피-헬먼 프로토콜의 실제 실행은 일반적으로 수백만 자리의 시계 크기를 이용하고 상상할 수 없을 정도로 많은 개인 수를 제작한다(이는 1032개보다도 훨씬 많다).
디피-헬먼 공개 수에서 가장 중요한 속성은 시계 크기가 소수(prime number)여야 한다는 점이다. 즉 이는 1과 자신 외에 어떤 약수도 갖지 않는다. 또 다른 매우 흥미로운 조건은 기저수가 시계 크기의 원시근(primitive root)이어야 한다는 점이다. 이는 기저수의 제곱수가 결국 시계에서 가능한 모든 값을 따라 순환한다는 뜻이다. 시계 크기 11에서의 거듭제곱 표를 다시 보면 2와 6은 11의 원시근이지만 3은 아니라는 사실을 알 수 있다. 3의 제곱수는 3, 9, 5, 4, 1을 따라 순환하고 2, 6, 7, 8, 10은 지나친다.
다른 공개 키 알고리즘은 이와 다르게 작동하고 이 덕분에 사람들은 의도한 수신자에게 보내는 메시지를 이 수신자가 발표한 공개 정보를 이용해 직접 암호화할 수 있다. 이와는 달리 키 교환 알고리즘은 수신자로부터 받은 공개 정보를 이용해 공유 비밀을 설정하지만 암호화 자체는 덧셈 트릭으로 이뤄진다. 인터넷상 대부분 통신에서 (이 장에서 공부한) 후자를 더 선호한다. 계산력이 훨씬 적게 필요하기 때문이다.
RSA(Rivest Shamir Adleman) :: 1977년 론 리베스트(Ron Rivest)와 아디 셰미르(Adi Shamir), 레오나르드 아델만(Leonard Adleman) 등 3명의 수학자에 의해 개발된 알고리즘을 사용하는 인터넷 암호화 및 인증시스템이다. 3명의 이름 가운데 첫 글자를 모아 붙인 용어이다. 마이크로소프트 윈도, 넷스케이프 브라우저를 비롯해 로터스 등 수백 개의 소프트웨어와 연동이 가능하며, 국제표준화기구(ISO)를 비롯하여, ITU·ANSI·IEEE 등 여러 국제기구에 암호표준으로 제안되어 있다. 소유권은 RSA시큐러티(Security)가 가지고 있다.
이 알고리즘은 두 개의 큰 소수(보통 140자리 이상의 수)를 이용한다. 이 수들의 곱과 추가연산을 통해 하나는 공개키를 구성하고 다른 하나는 개인키를 구성하는데, 사용되는 두 세트의 수 체계를 유도하는 작업이 수반된다. 이렇게 구성된 공개키와 개인키로 인터넷에서 사용하는 정보(특히 전자우편)를 암호화하고 복호화할 수 있는데, 동작원리는 매우 복잡한 수학으로 RSA 홈페이지에 상세하게 기술되어 있다.
개인키의 암호를 해독하려면 슈퍼컴퓨터로도 1만 년 이상이 소요되므로 공개키 암호방식의 대명사로서 거의 모든 분야에 응용되고 있다. 그러나 계산량이 많은 것이 단점으로 꼽힌다. 비트 수에 따라 다르나 펜티엄급 컴퓨터에서 공개키와 개인키를 만들려면 짧게는 20여 초, 길게는 몇 분까지 기다려야 한다. 복호화에도 많은 계산량이 요구되고 있어 휴대용 단말기에서는 사용하기 어렵다. 그러나 이런 문제를 해결하기 위해 최근에 타원곡선 알고리즘이 등장하기도 했다.
[네이버 지식백과] RSA [Rivest Shamir Adleman] (두산백과)
RSA 고안자들은 1970년대에 이 시스템의 특허를 냈고 이 특허권은 2000년대 후반까지 지속됐다.
5. 오류 정정 코드: 데이터 오류를 스스로 찾아 고치는 마법
오류 검출과 정정의 필요성
컴퓨터는 세 가지 근본적 작업을 수행한다. 가장 중요한 일은 계산 수행이다. 그리고 나머지 두 가지는 데이터 저장과 전송이다.
컴퓨터에 99.9999%의 정확성은 충분치 않다. 컴퓨터는 문자 그대로 수십억 조각의 정보를 단 하나의 실수도 없이 저장하고 전송할 수 있어야 한다.
반복 트릭
신뢰할 수 없는 채널을 통해 신뢰할 수 있는 통신을 가능케 하는 가장 기본적인 트릭은 우리가 잘 아는 방법이다. 정확한 정보를 확실히 전달하려면 이를 몇 번 반복할 필요가 있다는 것이다. 통화 품질이 좋지 않은 상황에서 어떤 사람이 전화번호나 은행 계좌 번호를 여러분에게 알려주는 경우 여러분은 아마도 실수가 없음을 확실히 하고자 최소한 한번 이상 반복해 달라고 요청할 것이다.
오류율이 높은 채널로 통신해야 할 수도 있다. 또, 반복해서 얻어진 최종 답은 우연히 찾은 것이며, 답이 늘 옳으리란 보장이 없다. 하지만 두 가지 문제 모두 매우 쉽게 처리할 수 있다. 원하는 만큼 신뢰도가 높아질 때까지 재전송 횟수를 늘리기만 하면 된다. 우리는 여기서, 신뢰할 수 없는 메시지라도 충분히 많이 반복하면 이를 우리가 원하는 정도로 신뢰할 만한 메시지로 만들 수 있다는 점을 알 수 있다.
리던던시 트릭
신뢰도를 높일 잉여 정보를 보내야 한다. 반복 트릭의 예에서 여러분이 보내는 잉여 정보는 여러 개의 원본 메시지 사본일 뿐이다. 컴퓨터과학자는 이런 잉여 정보를 ‘리던던시(redundancy)’라고 부른다. 때론 리던던시를 원본 메시지에 추가한다.
체크섬 트릭(the checksum trick(검사합 트릭)) :: 데이터의 정확성을 검사하기 위한 용도로 사용되는 합계. 오류 검출 방식의 하나이다. 대개는 데이터의 입력이나 전송 시에 제대로 되었는지를 확인하기 위해, 입력 데이터나 전송 데이터의 맨 마지막에 앞서 보낸 모든 데이터를 다 합한 합계를 따로 보내는 것이다. 데이터를 받아들이는 측에서는 하나씩 받아들여 합산한 다음, 이를 최종적으로 들어온 검사 합계와 비교하여 오류가 있는지를 점검한다.
[네이버 지식백과] 검사 합 [checksum, 檢査合] (IT용어사전, 한국정보통신기술협회)
5213.75달러를, 숫자의 20%를 무작위로 바꾸는 신뢰할 수 없는 통신 채널을 거쳐 전송하려 한다. ‘5213.75달러’를 전송하는 대신, 같은 정보를 담은 더 긴(그러므로 ‘잉여 정보를 담은’) 메시지로 변형하자.
five two one three point seven five(5 2 1 3 . 7 5)
이 메시지 글자의 약 20%가 상태가 좋지 않은 통신 채널 때문에 무작위로 다른 글자로 바뀐다고 가정하자. 메시지는 이렇게 바뀌었다.
fiqe kwo one thrxp point sivpn fivq
조금 읽기 힘들지만 영어를 아는 사람이라면 이 훼손된 메시지가 5213.75달러라는 진짜 은행 잔고를 반영한다고 추측할 수 있다.
핵심은 잉여 정보를 담은 메시지를 이용해서 메시지에 있는 모든 변화를 검출하고 정정할 수 있다는 점이다.
리던던시의 작동 원리를 정확히 살펴보지 않았지만 메시지를 더 길게 만드는 일과 관련이 있고 메시지의 각 부분은 일종의 잘 알려진 패턴을 따라야 한다. 이런 식으로 어떤 하나의 변형도 (알려진 패턴에 부합하지 않으므로) 확인할 수 있고 (오류를 패턴에 부합하게 바꿈으로써) 정정할 수 있다. 컴퓨터과학자는 이런 알려진 패턴을 ‘코드워드(code word)’라 부른다.
메시지는 컴퓨터 과학자가 ‘심벌(symbols)’이라고 부르는 요소로 구성된다. 현재 다루고 있는 간단한 예에서 심벌은 숫자 0~9이다. 각 심벌에 코드워드가 할당된다. 이 예에서 심벌 1에는 ‘one’이라는 코드워드가 할당되고 2에는 ‘two’라는 코드워드가 할당된다.
메시지를 전송하려면 우선 각 심벌을 이에 대응하는 코드워드로 해석(translation)해야 한다. 그 다음에 여러분은 변형한 메시지를 신뢰할 수없는 통신 채널을 통해 전송한다. 메시지를 수신했을 때 메시지의 각 부분을 보고 이것이 유효한 코드워드인지 확인한다. (예컨대 ‘five’처럼) 유효하다면 이에 대응하는 심벌로 이를 되돌리기만 하면 된다. 만약 확인한 메시지가 (‘fiqe’처럼) 유효한 코드워드가 아니라면 가장 근접히 부합하는 코드워드(여기선 ‘five’)를 알아낸 다음 이를 대응하는 심벌(이 경우엔 5)로 변형한다.

해밍 코드(Hammig code) :: 컴퓨터 스스로 데이터 오류를 찾아낼 수 있는 코드로, 수학자 리처드 웨슬리 해밍(Richard Wesley Hamming:1915∼1998)의 이름에서 유래되었다. 해밍이 1940년대 말에 벨전화연구소에서 개발하여 1950년 펴낸 저서에 소개한 이 코드는 패리티 검사(Parity Check) 등 보통의 에러 검출 코드들이 에러를 검출할 뿐 교정은 불가능한 것을 개선한 것으로, 대부분의 마이크로칩 디바이스에 채택되어 신뢰도를 높이는 데 사용된다. 오류를 수정하기 위해 재전송을 요구하기에는 시간이 많이 걸리는 원거리 장소로부터의 데이터 전송 신뢰도에 커다란 개선점을 제공한다. 특히 오늘날에는 휴대전화나 콤팩트디스크 등에서 신호의 오류를 수정하거나, 자료를 압축해 인터넷 속도를 향상시킬 때 유용하게 쓰인다.
[네이버 지식백과] 해밍 코드[Hammig code] (두산백과)

인코딩(encoding)할 때 4자리 숫자의 각 집단은 이에 추가할 리던던시를 가져 7자리 코드워드를 생성한다. 디코딩(decoding)할 때 수신자는 우선 수신한 7자리 숫자에 정확히 부합하는 코드워드를 찾는다. 정확히 부합하는 대상이 없다면 가장 근접한 값을 취한다. 이제 1과 0으로만 작업하므로 가장 근접한 값이 하나 이상일 수 있어 잘못 디코딩할 가능성도 있다고 우려하기 쉽다. 그러나 이 코드는 7자리 코드워드에 있는 어떤 하나의 오류도 명확히 정정될 수 있게 고안됐다.
컴퓨터과학자들은 ‘오버헤드(overhead)’라는 맥락에서 오류 정정 시스템의 비용을 측정한다. 오버헤드라는 메시지가 정확하게 수신되었는지 확인하기 위해 보내야 하는 잉여 정보의 양이다. 반복 트릭의 오버헤드는 그 양이 엄청나다. 이는 메시지 전체의 사본을 여러 번 보내야만 하기 때문이다. 리던던시 트릭의 오버헤드는 여러분이 사용하는 코드워드 집합의 정확한 구성에 달려있다.
영어 단어를 이용한 앞의 예에서 잉여 정보를 담은 메시지는 35자였던 반면 원본 메시지는 6자리 숫자로만 구성된다. 그러므로 리던던시 트릭을 적용하는 이 예에서 오버헤드도 꽤 크다. 이처럼 코드워드에 오버헤드가 적기 때문에 반복 트릭 대신 리던던시 트릭을 이용한다.
지금까지는 코드를 이용해 정보를 전송하는 예를 들었지만, 정보 저장에도 똑같이 잘 적용된다. CD, DVD, 컴퓨터 하드 드라이브는 모두 우리가 사용하면서 목격하는 놀라운 신뢰도를 달성하고자 오류 정정 코드에 상당히 의존한다.
체크섬 트릭
대부분 애플리케이션에서는 오류 검출이면 충분하다. 오류를 검출하면 데이터의 또 다른 사본을 요청할 수 있기 때문이다. 그리고 오류 없는 사본을 얻을 때까지 새로운 사본을 계속 요청할 수 있다. 이것은 매우 자주 사용되는 전략이다. 거의 모든 인터넷 접속은 이 기법을 이용한다. 이것을 ‘체크섬 트릭(checksum trick(검사합 트릭))’이라 부른다.
숫자 메시지의 단순 체크섬 계산은 정말 쉽다. 수신자는 메시지의 숫자를 취해 모두 더한 다음 결과에서 마지막 자릿수만 남기고 모두 버리면 된다. 이제 남는 숫자가 단순 체크섬이다.
4 6 7 5 6
모든 숫자의 합은 4+6+7+5+6 = 28이다. 그러나 마지막 자릿수만 유지하므로 이 메시지의 단순 체크섬은 8이다. 원본 메시지의 체크섬을 메시지끝에 첨부하기만 하면 된다. 그러면 수신자가 메시지를 수신할 때 체크섬을 다시 계산해서 결과를 송신자가 보낸 값과 비교해 정확한지 알 수 있다. 다시 말해 수신자는 메시지의 ‘합계(sum)’를 ‘검사(check)’한다. 그래서 ‘체크섬’이라는 용어를 쓴다.
4 6 7 5 6 8
수신자는 마지막 숫자인 8이 원본 메시지의 일부가 아니라는 사실을 즉시 인식할 수 있고 따라서 이를 한쪽에 치워 두고 나머지 숫자의 체크섬을 계산할 수 있다. 메시지 전송에서 오류가 없었다면 4+6+7+5+6 = 28을 계산하고 마지막 숫자(8)만 기억해 뒀다가 이전에 치워둔 체크섬과 같은지 검사하고 메시지가 정확히 전송됐다고 판단한다.
체크섬이 일치 하지 않으면 메시지의 재전송을 요청하고 새로운 사본을 받을 때까지 기다렸다가 다시 계산해서 체크섬을 비교한다. 체크섬이 들어맞는 메시지를 받을 때까지 이 과정을 계속한다.
오류 정정 시스템의 ‘오버헤드’는 송신자가 메시지 자체에 추가로 보내야 하는 잉여 정보의 양이란 사실을 상기하라. 이 단순 체크섬은 메시지에서 하나의 오류만을 검출할 수 있다. 두 개 이상의 오류가 있을 경우 단순 체크섬은 이를 검출할 수도 있지만 검출하지 못할 수도 있다.

하나의 오류만 있는 경우 단순 체크섬은 이를 100% 검출한다.
체크섬 트릭에 몇 가지 수정을 추가해 이 문제를 다룰 수 있다. 첫 단계는 새로운 유형의 체크섬을 정의하는 것이다. 이를 계산하는 과정이 계산을 오르는 것이라 생각하면 도움이 되므로 이를 ‘계단(staircase)’ 체크섬이라 하자. 메시지의 각 숫자에 해당 계단 숫자를 곱한 값들의 합계를 구한다. 이를 ‘계단합’이라 하겠다. 마지막으로 단순 체크섬에서와 마찬가지로 마지막 자릿수만 빼고 버린다.
4 6 7 5 6
(1×4)+(2×6)+(3×7)+(4×5)+(5×6) = 4+12+21+20+30 = 87
이제 계단합에서 마지막 자릿수인 7만 남긴다. 그러므로 ‘46756’의 계단 체크섬은 7이다.
단순 체크섬과 계단 체크섬을 모두 포함하면 메시지에 있는 몇 가지 오류라도 확실히 검출할 수 있다. 그러므로 우리의 새로운 체크섬 트릭은 원본 메시지 다음에 두 개의 여분 숫자를 더해 전송한다. 즉 단순 체크섬을 원본 메시지 다음에 먼저 쓰고 계단 체크섬을 마지막에 쓴다. 예를 들어 ‘46756’이라는 메시지는 이렇게 전송한다.
4 6 7 5 6 8 7
계산한 두 체크섬이 받은 체크섬과 같다면 메시지는 확실히 정확하거나 세 개 이상의 오류를 갖고 있다는 뜻이다.

체크섬 트릭은(10자리 미만의) 상대적으로 짧은 메시지에만 효과를 보장한다는 사실을 인식해야 한다. 그러나 이와 매우 유사한 아이디어를 더 긴 메시지에도 적용할 수 있다. 숫자의 덧셈, 숫자를 다양한 형태의 ‘계단’과 곱하기, 고정된 패턴에 따라 일부 숫자 바꾸기 같은 일련의 단순한 계산으로 체크섬을 정의할 수 있다.
실제 체크섬은 주로 이보다 훨씬 많은 자릿수를 생산한다. 때론 150개 정도의 자릿수를 만들 때도 있다. 매우 긴 메시지에 대해선 150개의 숫자처럼 상대적으로 큰 체크섬도 메시지 자체에 비해선 매우 적은 비율일 뿐이다.
모든 체크섬이 오류 검출에 실패하지 않는 것은 아니다. 컴퓨터과학자들은 암호학적 해시 함수(cryptographic hash function)라 부르는 특정 유형의 체크섬을 요한다.
암호화 해시 함수(cryptographic hash function) :: 해시 함수의 일종으로, 해시 값으로부터 원래의 입력값과의 관계를 찾기 어려운 성질을 가지는 경우를 의미한다. 암호화 해시 함수가 가져야 하는 성질은 다음과 같다.
역상 저항성(preimage resistance): 주어진 해시 값에 대해, 그 해시 값을 생성하는 입력값을 찾는 것이 계산상 어렵다. 즉, 제 1 역상 공격에 대해 안전해야 한다. 이 성질은 일방향함수와 연관되어 있다.
제 2 역상 저항성(second preimage resistance): 입력 값에 대해, 그 입력의 해시 값을 바꾸지 않으면서 입력을 변경하는 것이 계산상 어렵다. 제 2 역상 공격에 대해 안전해야 한다.
충돌 저항성(collision resistance): 해시 충돌에 대해 안전해야 한다. 같은 해시 값을 생성하는 두 개의 입력값을 찾는 것이 계산상 어려워야 한다.
즉, 입력값과 해시 값에 대해서, 해시 값을 망가뜨리지 않으면서 입력값을 수정하는 공격에 대해 안전해야 한다. 이러한 성질을 가지는 해시 값은 원래 입력값을 의도적으로 손상시키지 않았는지에 대한 검증 장치로 사용할 수 있다.
순환 중복 검사(CRC)와 같은 몇몇 해시 함수는 암호 안전성에 필요한 저항성을 가지지 않으며, 우연적인 손상을 검출할 수는 있지만 의도적인 손상의 경우 검출되지 않도록 하는 것이 가능하기도 하다. 가령, 유선 동등 프라이버시(WEP)의 경우 암호화 해시 함수로 CRC를 사용하나, CRC의 암호학적 취약점을 이용한 암호공격이 가능하다는 것이 밝혀져 있다.
[위키백과] 암호화 해시 함수[cryptographic hash function]
해시함수 :: 요약함수(要約函數)·메시지다이제스트함수(message digest function)라고도 한다. 주어진 원문(原文)에서 고정된 길이의 의사난수(疑似亂數)를 생성하는 연산기법이다. 생성된 값은 '해시값'이라고 한다.
통신회선을 통해서 데이터를 주고받을 때, 경로(經路)의 양쪽 끝에서 데이터의 해시값을 구해서, 보낸 쪽과 받은 쪽의 값을 비교하면 데이터를 주고받는 도중에 여기에 변경이 가해졌는지 어떤지를 확인할 수 있다.
불가역적(不可逆的)인 일방향함수를 포함하고 있기 때문에 해시값에서 원문을 재현할 수는 없다. 또한, 같은 해시값을 가진 다른 데이터를 작성하는 것도 극히 어렵다. 이런 특성을 이용해서 통신의 암호화 보조수단이나 사용자 인증, 디지털 서명 등에 응용되고 있다.
일방향함수란 함정문함수(trap door function)라고도 하는 것으로, 제수(除數)에서 결과를 구하는 것은 간단하지만, 결과에서 제수를 구하는 것을 어려운 함수를 말한다.
[네이버 지식백과] 해시함수 [hash function] (두산백과)
핀포인트 트릭
코드워드를 제작하는 방법으로 오류를 재빨리 집어내는 리던던시 트릭의 매우 특수한 예를 ‘핀포인트(pinpoint) 트릭’이라 부르겠다.
메시지가 정확히 16자리라고 가정하자. 이 역시 실제 기법을 제한하진 않는다. 이보다 긴 메시지라면 이를 16자리 집합으로 쪼개서 각 집합을 별개로 작업하면 된다. 메시지가 16자리보다 짧다면 16자리가 될 때까지 0을 채워 넣으라. 핀포인트 트릭에서 첫 단계는 메시지의 16자리 숫자를 왼쪽에서 오른쪽, 위에서 아래로 읽는 상자 안에 재정렬해 넣는 일이다. 예를 들어 보자. 실제 메시지는 이렇다.
4 8 3 7 5 4 3 6 2 2 5 6 3 9 9 7
이를 다음과 같이 재정렬한다.

이제 각 행의 단순 체크섬을 계산하고 이를 각 행의 오른편에 추가한다.

두 번째 단계는 각 열의 단순 체크섬을 계산해 맨 아래 행에 추가하는 일이다.

세 번째 단계는 한 번에 하나의 숫자만 저장하거나 전송할 수 있도록 모든 숫자를 재배열하는 일이다. 상자 안의 숫자를 왼쪽에서 오른쪽으로, 위에서 아래로 읽는 순서대로 한다.
4 8 3 7 2 5 4 3 6 8 2 2 5 6 5 3 9 9 7 8 4 3 0 6
수신자가 받은 16자리 숫자 메시지가 다음과 같다고 하자.
4 8 3 7 2 5 4 3 6 8 2 7 5 6 5 3 9 9 7 8 4 3 0 6
첫 단계는 5×5 표에 이 숫자를 배치해서 마지막 열과 행이 원본메시지에 첨부된 체크섬에 대응하도록 정렬하는 작업이다.

다음 단계에선 각 열과 행에 있는 첫 네 숫자의 단순 체크섬을 계산해서 수신자가 받은 체크섬 값 옆에 새로 만든 열과 행에 계산 결과를 기록한다.

체크섬 값이 두 집합이라는 점을 명심해야 한다. 하나는 수신자가 받은 값이고 다른 하나는 수신자가 계산한 값이다.
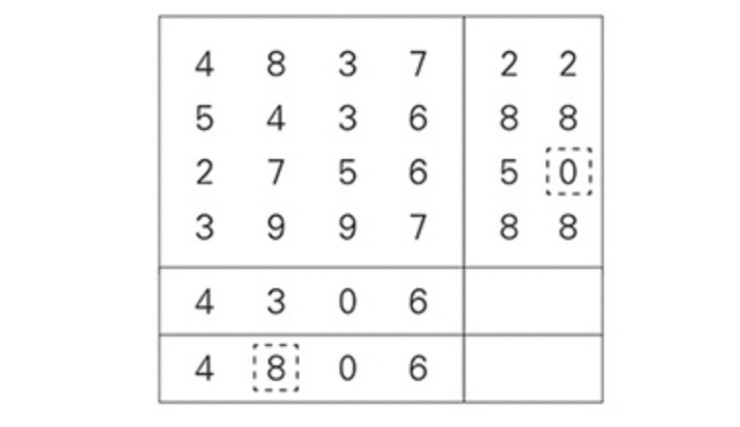
두 값의 차이가 나는 위치가 통신 오류가 발생한 지점을 정확히 말해 준다! 오류는 (다른 모든 행은 정확한 체크섬을 가지므로) 셋째 행에 있어야만 하고 (다른 모든 열이 정확한 체크섬을 가지므로) 둘째 열에 있어야만 한다. 그리고 다음 도표에서 보듯, 오류의 위치는 정확히 하나로 좁혀진다.

오류인 7을, 두 체크섬을 모두 정확히 만들 숫자로 교체하기만 하면 된다.
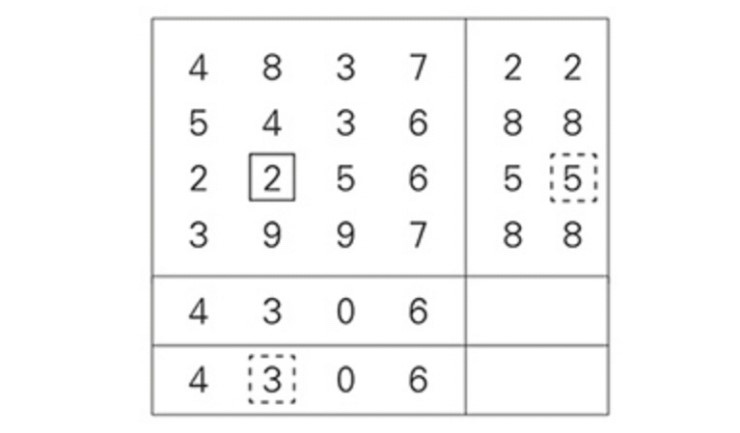
마지막 단계는 5×5 상자로부터 정정한 16자리 숫자 원본 메시지를 추출하는 일이다. 여기선 (당연히 마지막 열과 행을 무시하고) 위에서 아래로, 왼쪽에서 오른쪽으로 읽으면 된다.
4 8 3 7 5 4 3 6 2 2 5 6 3 9 9 7
이는 원본 메시지와 정확히 일치한다. 컴퓨터과학에서는 핀포인트 트릭을 ‘이차원 패리티(two-dimensional parity)’라 부른다. 패리티란 컴퓨터가 통상 쓰는 이진수로 작동하는 단순 체크섬을 뜻한다. 그리고 메시지를 이차원 격자(grid(행과 열))에 배열하기에 이차원 패리티라고 부른다. 이차원 패리티를 일부 실제 컴퓨터에 이용했지만 이는 그 어떤 리던던시 트릭보다 비효율적이다.
실제 오류 정정과 검출
오류 정정 코드는 정보 이론(information theory)이라는 더 큰 분야의 하나일 뿐이고 대부분 과학자는 클로드 섀넌의 1948년 논문 <수학적 통신 이론(The Mathematical Theory of Communication)>을 정보 이론 분야의 탄생으로 간주한다.
해밍 코드는 초창기 컴퓨터에 도입됐을 뿐만 아니라, 지금도 특정 유형의 메모리 시스템에서 널리 이용된다. 또 다른 중요한 코드의 하나는 리드-솔로몬 코드다. 리드-솔로몬 코드는 유한체 대수라는 수학의 분야에 기초하고 있다. 하지만 계단 체크섬과 이차원 핀포인트 트릭의 특징을 결합한 것으로, 대강 이해해도 무방하다. 오늘날 CD, DVD, 하드 디스크에 이용된다.
리드-솔로몬 코드 :: 리드(Reed)와 솔로몬(Solomon)이 제안한 군집 형태의 오류를 정정할 수 있는 비2원 BCH 부호의 하나. 자기 테이프나 디스크 표면의 손상 또는 먼지는 군집 오류를 발생시키므로 리드 솔로몬 부호를 적용한다. RS(204,188) 리드 솔로몬 부호는 입력이 188바이트일 때 16바이트를 붙여 전송하면 8바이트의 오류를 완벽하게 정정함을 나타낸다. 또한 군집 오류 정정 능력이 뛰어난 특성을 이용하여, 산발 오류에 대한 정정 능력이 뛰어나 지상 무선 통신 분야와 유선 통신 및 암호 통신에 널리 쓰이는 돌림형 부호와 연결하여 산발 오류와 군집 오류가 동시에 발생하는 환경인 우주 통신이나 위성 통신, 위성 방송에 사용함으로써 채널 오류를 강력히 제거하고 있다. 이동 통신 시스템, 대역 확산 시스템 등의 통신 시스템과 컴퓨터 기억 장치, 콤팩트디스크(CD)와 디지털 녹음기(DAT) 같은 저장 매체의 오류 정정에 널리 적용되고 있으며, DVB(digital video broadcast)에서는 전송 표준으로 채택하고 있다.
[네이버 지식백과] 리드 솔로몬 부호 [Reed-Solomon code, R-S code, -符號] (IT용어사전, 한국정보통신기술협회)
일반적으로 체크섬은 오류 정정보다 오류 검출에 널리 사용된다. 아마도 가장 보편적인 예는 이더넷(Ethernet)일 듯하다.
이더넷(Ethernet) :: 가장 대표적인 버스 구조 방식의 근거리통신망(LAN). 미국의 제록스(Xerox Corporation), 미니컴퓨터 제조회사인 디지털이퀴프먼트와 반도체 제조회사인 인텔(Intel Corporation)이 공동으로 개발하여 1980년에 상품화하고 특허를 받았다. LAN은 컴퓨터 제조회사가 각기 나름대로 개발하고 있으나 LAN의 국제표준화를 추진하고 있는 미국전기전자기술자협회(IEEE)의 표준방식의 하나로서 채용되고 있다.
이더넷은 데이터 전송을 위해 다음과 같은 내용의 CSMA/CD(carrier sense multiple access with collision detection) 방식을 사용한다. 데이터를 보내려는 컴퓨터가 먼저 통신망이 사용 중인지 아닌지 검사한 후에 비어 있을 때 데이터를 보낸다. 통신망이 사용 중이면 일정시간을 기다린 후 다시 검사한다. 통신망이 사용 중인지는 전기적인 신호로 확인할 수 있다.
만약 두 대의 컴퓨터가 동시에 검사하여 통신망이 사용 중이지 않다는 것을 확인하고 동시에 전송하게 되면 충돌이 발생한다. 이런 경우에 대비해서 데이터를 전송한 컴퓨터는 자신의 데이터가 손상되지 않았는지를 확인하여 손상이 있으면 다시 전송하게 된다. 이때 두 컴퓨터의 재전송이 동일한 시간 후에 일어나면 다시 충돌이 발생하므로 재전송 시간은 일정한 방법에 의해 변경된다.
[네이버 지식백과] 이더넷 [Ethernet] (두산백과)
CRC :: 순환 중복 검사(巡環重復檢査), CRC(cyclic redundancy check)는 네트워크 등을 통하여 데이터를 전송할 때 전송된 데이터에 오류가 있는지를 확인하기 위한 체크값을 결정하는 방식을 말한다.
데이터를 전송하기 전에 주어진 데이터의 값에 따라 CRC 값을 계산하여 데이터에 붙여 전송하고, 데이터 전송이 끝난 후 받은 데이터의 값으로 다시 CRC 값을 계산하게 된다. 이어서 두 값을 비교하고, 이 두 값이 다르면 데이터 전송 과정에서 잡음 등에 의해 오류가 덧붙여 전송된 것 임을 알 수 있다.
CRC는 이진법 기반의 하드웨어에서 구현하기 쉽고, 데이터 전송 과정에서 발생하는 흔한 오류들을 검출하는 데 탁월하다. 하지만 CRC의 구조 때문에 의도적으로 주어진 CRC 값을 갖는 다른 데이터를 만들기가 쉽고, 따라서 데이터 무결성을 검사하는 데는 사용될 수 없다. 이런 용도로는 MD5 등의 함수들이 사용된다.
순환 중복 검사를 계산하는 과정은 하드웨어적 방식과 소프트웨어적 방식을 생각할 수 있다. 하드웨어적 방식을 말할 때, 직렬데이터를 계산하는 것이 단순하다. 통신시스템에서 프로토콜 계층에서 물리층에 가까울 수록 하드웨어 접근을 그리고 상위계층에 가까울 수록 소프트웨어적인 방식이 적용된다.
통신시스템에서 물리계층에 가까울수록 직렬데이터를 사용하는 경향이 있다. 따라서 하드웨어적 계산방식을 사용 한다. 전송라인은 거의 직렬 데이터이기 때문이다. 이런 경우 순환 중복 검사는 비트단위의 입력에 대한 출력을 얻는다. 논리 회로를 만들면 간단해 진다. 그러나 높은 계층으로 갈수록 병렬데이터(octet 단위, 8비트)를 사용한다. 이런경우는 소프트웨어적 접근으로 주로 바이트 단위로 계산한다. 순환 중복 검사는 결국 비트단위 입력에 대한 각 비트별 XOR 연산이므로 한바이트 계산도 소프트웨어적 고속계산에 한계가 있다. 이런경우 주로 미리계산을 한 테이블 형태를 사용한다.
[위키백과] 순환 중복 검사[巡環重復檢査]
TCP :: 전송 제어 프로토콜(Transmission Control Protocol, TCP, 문화어: 전송조종규약)은 인터넷 프로토콜 스위트(IP)의 핵심 프로토콜 중 하나로, IP와 함께 TCP/IP라는 명칭으로도 널리 불린다. TCP는 근거리 통신망이나 인트라넷, 인터넷에 연결된 컴퓨터에서 실행되는 프로그램 간에 일련의 옥텟을 안정적으로, 순서대로, 에러없이 교환할 수 있게 한다. TCP는 전송 계층에 위치한다. 네트워크의 정보 전달을 통제하는 프로토콜이자 인터넷을 이루는 핵심 프로토콜의 하나로서 국제 인터넷 표준화 기구(IETF)의 RFC 793에 기술되어 있다.
TCP는 웹 브라우저들이 월드 와이드 웹에서 서버에 연결할 때 사용되며, 이메일 전송이나 파일 전송에도 사용된다.
TCP의 안정성을 필요로 하지 않는 애플리케이션의 경우 일반적으로 TCP 대신 비접속형 사용자 데이터그램 프로토콜(User Datagram Protocol)을 사용한다. 이것은 에러 확인 및 전달 확인 기능이 없는 대신 오버헤드가 작고 지연시간이 짧다는 장점이 있다.
[위키백과] 전송 제어 프로토콜[Transmission Control Protocol, TCP]
청크(chunk) :: 규칙 기반 시스템에서 단일 단위로서 저장·검색되는 사실의 집합체.
[네이버 지식백과] 청크 [chunk] (컴퓨터인터넷IT용어대사전, 2011.1.20., 일진사)
패킷(packet) :: 네트워크를 통해 전송하기 쉽도록 자른 데이터의 전송단위. 본래는 소포를 뜻하는 용어로, 소화물을 뜻하는 패키지(package)와 덩어리를 뜻하는 버킷(bucket)의 합성어이다. 우체국에서는 화물을 적당한 덩어리로 나눠 행선지를 표시하는 꼬리표를 붙이는데, 이러한 방식을 데이터통신에 접목한 것이다. 즉, 데이터 전송에서 송신측과 수신측에 의하여 하나의 단위로 취급되어 전송되는 집합체를 의미한다. 전자우편이나 HTML·GIF 등 어떤 종류의 파일에도 적용할 수가 있다. 이때 분할된 각각의 패킷에는 별도의 번호가 붙여지고 목적지의 인터넷 주소가 기록되며, 에러 체크 데이터도 포함된다.
파일을 분할해서 전송하지만 수신하는 곳에서는 원래의 파일로 다시 재조립된다. 헤더와 데이터·테레일러로 이루어져 있는데, 헤더에는 데이터가 전달될 주소와 순서 등이 기록되고, 테레일러에는 에러 정보가 기록된다. 보통 2계층으로 내려가기 전까지 3·4계층의 데이터 단위는 패킷이라고 하고, 1·2 계층의 데이터 단위는 프레임이라고 한다. 일반적으로 128바이트가 표준이지만 32·64·256바이트와 옥텟 등 편의에 따라 크기를 바꿀 수 있다.
내부에 상대방의 주소를 갖고 있기 때문에 신뢰도가 높으며, 에러를 체크하는 등 고품질의 전송을 제공할 수 있는 장점이 있다. 또 통신망을 경제적으로 구성할 수 있고, 전송속도와 코드를 바꿀 수 있으므로 서로 다른 기종을 사용하는 사용자들끼리도 통신이 가능하다. 다양한 부가 서비스도 가능하며, 국제적으로 표준화된 프로토콜을 사용하여 인터넷 상에서 데이터를 전송할 때 매우 효율적이다. 패킷형 단말기와 교환기 사이의 인터페이스에 사용되는 권장 프로토콜은 X.25이며, 비표준 단말기와의 인터페이스에는 X.3과 X.28이다.
[네이버 지식백과] 패킷 [packet] (두산백과)
저밀도 패리티 검사 코드(low-density parity-check code) :: IEEE 802.16e 휴대 인터넷 국제 표준에 제안되고 있는 채널 코딩 기술. 부호의 검사 행렬에서 행의 1의 숫자와 열의 1의 숫자가 미리 정해져 있는 블록 부호로서 행과 열의 1의 숫자가 부호어의 길이에 비해 매우 작기 때문에 검사 행렬이 저밀도(low density)가 된다. 고속 데이터 전송 시 성능이 탁월하고, 디코딩에 사용되는 BP(Belief Propagation) 알고리듬 또한 하드웨어 구현 시 전체적으로 병렬 프로세싱이 가능하여 고속 데이터 전송에 적합하다. 다만, 인코딩할 때 많은 계산량을 요구하는 점이 단점으로서 여러 가지 해결 방안이 연구되고 있다. 1963년 Robert Gallager 씨가 발명하였으나 최근에야 효용성이 인정되고 있다.
[네이버 지식백과] 저밀도 패리티 체크 코드 [Low Density Parity Check Code, 低密度-] (IT용어사전, 한국정보통신기술협회)
6. 패턴 인식과 인공지능: 사람처럼 학습하고 생각하는 컴퓨터
에이다 러브레이스 :: 1815년 12월 10일 영국의 낭만파 시인 바이런(1788~1824)의 딸로 태어나, 어렸을 때부터 수학에 비상한 재능을 보였다. 1835년 윌리엄 킹 러브레이스와 결혼했으며 결혼 3년 후 남편이 작위를 받으면서 그녀 역시 백작 부인이 된다.
평범한 귀족부인으로 살면서 무료함을 느껴가던 중 발명가이자 케임브리지대 교수인 찰스 베비지(Charles Babbage, 1791~1871)의 발명품소개회에 참석하면서, 그의 후원자 겸 동료가 된다. 당시 베비지는 모든 종류의 계산을 가능하게 하는 계산기계인 해석기관(analytical engine)을 설계 중이었는데, 에이다는 베비지의 해석기관이 원활하게 작동할 수 있도록 설정된 조건을 만족하는 한 같은 계산이 반복되도록 하는 ‘루프(loop)’, 전체 프로그램에 포함되어 필요할 때마다 사용한 공식을 다시 사용하는 ‘서브루틴(subroutine)’, 구문을 건너 뛰어 실행하는 ‘점프(jump)’, 조건식이 달린 구문인 ‘if’ 등의 소프트웨어를 만들었다.
그리고 1842년 베비지와 함께 해석기관에 대한 연구를 바탕으로 한 <베비지의 해석기관에 대한 분석(Observations on Mr. Babbage’s Analytical Engine)>을 출판하게 된다. 베비지는 에이다의 재능에 감탄해 그녀를 '숫자의 마술사(enchantress of numbers)'라고 불렀다고 전해진다. 또한 러브레이스는 찰스 배버지의 기계인 '해석기관(analytical engine)'에 관한 노트를 남겼는데, 그 노트는 기계가 작동하는 방식을 적은 최초의 '알고리즘'이라고 한다. 이 때문에 러브레이스는 최초의 프로그래머라는 명성을 후일 얻게 된다. 그러나 그녀는 도박에 빠져 많은 재산을 탕진하고, 1852년 36살의 나이에 자궁암으로 사망했다.
한편 생전에 알려져 있지 않았던 그녀의 이름은 100년이 지나서야 세상에 알려지게 된다. 1975년 미 국방부는 서로 난립하는 컴퓨터 프로그래밍 언어들을 통합하기 위한 작업을 완료한 뒤 이 언어를 ‘에이다’라고 명명해, 에이다를 ‘최초의 프로그래머’로 인정했다.
[네이버 지식백과] 에이다 러브레이스 [Ada Lovelace] (시사상식사전, 박문각)
패턴 인식의 기본 과제는 (여러 사람이 각각 다른 조명 아래서 찍은 얼굴 사진이나, 여러 사람이 쓴 손글씨 샘플처럼) 극도로 가변적인 데이터를 취해 유용한 일을 하는 데 있다. 인간은 이런 데이터를 의심의 여지 없이 지적으로 처리할 수 있다. 인간은 불가사의할 정도로 정확하게 얼굴을 인식하고, 사전에 손글씨 견본을 보지 않고도 누군가의 글씨를 읽을 수 있다. 컴퓨터는 이런 과제에서 인간보다 매우 열등하다.
무엇이 문제인가?
표준 접근은 패턴 인식을 분류 문제로 인식하는 것이다. 처리될 데이터를 샘플이라는 합리적인 청크로 나눠 각 샘플이 클래스(class)라는 고정된 집합의 하나에 속한다고 가정한다. 어떤 문제에선 클래스가 두 개뿐이다. 이에 관한 흔한 예는 ‘건강한’ 집단과 ‘아픈’ 집단으로 나뉘는 특정 질병에 대한 의학적 진단에서 찾을 수 있다.
컴퓨터의 과제는 전에 본 적 없는 새로운 데이터 샘플을 처리해 가능한 클래스 중 하나로 분류하는 일이다.
분명히 컴퓨터는 손으로 쓴 숫자의 모양을 식별하는 지식을 탑재하지 않았다. 사실 인간도 이런 지식을 타고나지는 않았다. 인간은 명시적 교육(explicit teaching)과 스스로 예를 찾아 보면서 이해하는 자가 교육 과정을 거쳐 숫자 등의 다양한 손글씨를 인식하는 법을 배운다. 이 두 가지 전략을 컴퓨터 패턴 인식에도 이용한다. 그러나 가장 단순한 과제를 제외하곤 컴퓨터에 대한 명시적 교육은 비효율적이다.
컴퓨터가 손글씨 같은 흥미로운 분류 과제를 풀도록 명시적으로 교육할 수는 없다. 그래서 컴퓨터과학자는 컴퓨터가 샘플의 분류법을 자동으로 ‘학습’하게 하는 또 다른 전략을 지향한다. 기본 전략은 컴퓨터에게 엄청난 양의 분류된 데이터(labeled data)를 주는 것이다. 즉 이미 분류된 샘플을 제공한다.
각 샘플엔 라벨(label)(즉 클래스)이 있기 때문에 컴퓨터가 다양한 분석 트릭을 이용해 각 클래스의 특징을 추출할 수 있다. 나중에 컴퓨터는 분류되지 않은 샘플을 보면 이와 가장 유사한 특징을 가진 라벨을 선택해서 클래스를 추측할 수 있다. 각 클래스의 특징을 학습하는 과정을 대개 ‘훈련(training)’이라고 부르고 분류된 데이터는 ‘훈련 데이터’다. 따라서 아주 간단히 패턴 인식 과제를 두 단계로 나눈다. 첫째는 분류된 훈련 데이터를 기반으로 컴퓨터가 클래스에 관해 학습하는 ‘훈련 단계’이고, 둘째는 컴퓨터가 분류되지 않은 새로운 데이터 샘플을 나누는 ‘분류 단계’다.

인접이웃 트릭

인접이웃분류자(nearest-neighbor classifier)라고 부르는 접근 방식이다. 가장 단순한 형태의 인접이웃 트릭은 문자 그대로의 작업을 한다. 분류되지 않은 데이터샘플을 받으면 우선 훈련 데이터에서 이 샘플에 가장 근접한 이웃을 찾아 이 최근접 이웃의 클래스를 예측값으로 이용한다.

다양한 종류의 인접이웃

숫자 이미지 사이의 지리적 거리가 아니라 차이를 측정하는 것이다. 차이는 백분율로 측정하겠다. 1%만 차이 나는 이미지는 매우 가까운 이웃이고, 99% 차이 나는 이미지는 거의 관계가 없다. (일반적 패턴 인식 과제에서처럼 입력은 처리 단계를 거친다. 이 경우 각 숫자는 모두 같은 크기로 조정되고 이미지의 가운데로 정렬된다)
이런 종류의 전형적 시스템은 10만 개의 라벨을 붙인 예를 이용한다. 이제 시스템은 분류되지 않은 새로운 손글씨 숫자가 나오면 10만 개의 예를 모두 검색해 분류된 숫자와 가장 가까운 예를 하나 찾는다.
이런 유형의 ‘인접이웃’ 거리를 이용하는 시스템은 약 97%의 정확도로 잘 작동한다. 인접이웃 분류자는 최신 거리 측정 기술을 이용해 손으로 쓴 숫자에 대해 99.5% 이상의 정확도를 달성할 수 있다.
서포트 벡터 머신(support vector machine) :: 서포트 벡터 머신은 범주 간 경계를 찾되, 데이터 개체로부터의 거리, 즉 마진(margin)을 최대로 하는 경계를 찾는 것이 특징이다. 경계를 찾을 때 모든 데이터 개체를 고려할 필요가 없고 경계에 가까운 개체, 즉 서포트 벡터만 고려하면 된다. 따라서 학습이 매우 효율적으로 이루어질 수 있고, 아웃라이어의 영향을 별로 받지 않는다.
이해의 편의를 위해 변수의 차원이 2이고 범주도 2개인 경우를 생각해 보자. 데이터 개체들을 2차원 평면에 점으로 나타낼 수 있는데, 범주1에 속하는 점들은 서로 몰려서 나타나고 범주2에 속하는 점들도 서로 몰려서 나타나고 이 두 범주 사이에 어느 정도의 여백이 존재할 것이다. 이 여백을 통과하여 두 범주를 가르는 경계는 [변수의 차원 개수 – 1]의 차원을 갖는 초평면(hyperplane)인데(변수의 차원이 2인 경우 경계는 1차원의 직선), 그러한 경계는 매우 많이 존재할 수 있으나 두 범주의 개체들로부터 최대한 멀리 떨어질수록 좋다고 할 수 있다. 경계에 가장 가까운 개체를 서포트 벡터라고 하는데, 서포트 벡터는 [변수의 차원 개수 + 1]개 이상 존재한다. 서포트 벡터들을 바탕으로 최적의 경계를 찾는 것이 핵심이 된다.
오분류(misclassification)를 허용하지 않는 경성 마진(hard margin)을 사용할 수도 있으나, 그럴 경우 경계가 너무 복잡해지고 과적합(overfitting)의 우려도 있으므로, 약간의 오분류를 허용하는 연성 마진(soft margin)을 사용하는 것이 일반적이다.
서포트 벡터 머신은 기본적으로 2진 분류기이지만, 2진 분류기들을 여럿 조합하여 다중 범주 분류도 가능하다. 하나 대 나머지(one versus rest) 방식으로 범주 개수 n만큼의 2진 분류기를 조합할 수도 있고, 하나 대 하나(one versus one) 방식으로 nC2개 만큼의 2진 분류기를 조합할 수도 있다. 또한 서포트 벡터 머신은 기본적으로 분류기이지만 수치형 타깃 변수를 예측하는 회귀 과제에도 사용할 수 있다.
[네이버 지식백과] 서포트 벡터 머신 (AI 용어사전)
콘볼루션 신경망(convolutional neural network) :: 심층 신경망(DNN: Deep Neural Network)의 한 종류로, 하나 또는 여러 개의 콘볼루션 계층(convolutional layer)과 통합 계층(pooling layer), 완전하게 연결된 계층(fully connected layer)들로 구성된 신경망.
CNN은 2차원 데이터의 학습에 적합한 구조를 가지고 있으며, 역전달(Backpropagation algorithm)을 통해 훈련될 수 있다. 영상 내 객체 분류, 객체 탐지 등 다양한 응용 분야에 폭넓게 활용되는 DNN의 대표적 모델 중 하나이다.
[네이버 지식백과] 콘볼루션 신경망 [Convolutional Neural Network, -神經網] (IT용어사전, 한국정보통신기술협회)
스무고개 트릭:의사결정나무
좋은 질문은 많은 양의 ‘정보’ 제공을 보장하지만 나쁜 질문은 그렇지 않다. 예를 들어 처음부터 “구리로 만들어졌니?” 같은 질문을 던지는 건 적절하지 않다. 답이 ‘아니요’라면 가능성의 범위가 거의 좁아지지 않기 때문이다. 좋은 질문과 나쁜 질문에 관한 이런 직관이 정보 이론이라는 매력적인 분야의 중심에 있다. 그리고 이는 의사결정나무(decision tree)라는 단순하고 강력한 패턴 인식 기법의 핵심이기도 하다.
충분한 양의 훈련 데이터가 주어지면 정확한 분류를 만들어낼 의사결정나무를 학습하는 일이 가능하다.
검색엔진은 웹 스팸을 확인하고 제거하기 위해 엄청난 노력을 기울인다. 이는 패턴 인식에 완벽히 해당하는 애플리케이션이다. 사람이 많은 양의 훈련 데이터(이 예에선 웹페이지)를 얻고 이에 ‘스팸’ 또는 ‘스팸 아님’이라는 라벨을 손수 붙인 다음 일종의 분류자를 훈련시킨다. 이는 정확히 마이크로소프트 리서치가 2006년에 수행한 작업이다. 마이크로소프트 리서치에서는 오랫동안 널리 사용돼 온 기법인 의사결정나무가 이 문제에 있어 가장 좋은 성능을 보이는 분류자임을 알아냈다.

웹 스패머들은 인기 있는 단어를 많이 집어 넣어 랭킹을 높이고 싶어 한다. 따라서 인기 있는 단어가 적게 포함됐다는 사실은 스팸일 가능성이 낮다는 뜻이다. 이는 이 의사결정나무에서 첫 번째 결정을 의미하며 다른 결정도 이와 비슷한 논리를 따른다. 이 의사결정나무는 약 90%의 정확도를 달성한다.
의사결정나무 자체의 세부 내용이 아니라 컴퓨터 프로그램이 약 1만 7,000개의 웹페이지에서 가져온 훈련 데이터를 토대로 전체 나무를 자동으로 생성했다는 사실이 더욱 중요하다.
의사결정나무의 학습 과정은 기본적으로는, 잘 짜인 스무고개 게임을 계획하는 것과 같다. 컴퓨터는 매우 많은 수의 첫 질문을 시험해 보고 최적의 정보를 도출할 질문을 찾는다. 첫 질문에 대한 답을 토대로, 훈련 예시를 두 집단으로 나눈 다음 각 집단에 최적의 질문을 제시한다. 의사결정나무 분류자의 학습 단계는 복잡할 수 있지만 이는 완전히 자동이고 사람은 이를 단 한 번만 하면 된다.
신경망
튜링 테스트(Turing test) :: 영국의 수학자 앨런 튜링(Alan Turing)이 제안한 인공지능 판별법을 말한다. 1950년 튜링은 〈계산기계와 지성 Computing Machinery and Intelligence〉이라는 논문을 통하여 기계(컴퓨터)가 사람처럼 생각할 수 있다는 견해를 제시하였다. 그는 이 논문에서 컴퓨터와 대화를 나누어 컴퓨터의 반응을 인간의 반응과 구별할 수 없다면 해당 컴퓨터가 사고(思考)할 수 있는 것으로 간주하여야 한다고 주장하였으며, 50년 뒤에는 보통 사람으로 구성된 질문자들이 5분 동안 대화를 한 뒤 컴퓨터의 진짜 정체를 알아낼 수 있는 확률이 70%를 넘지 않도록 프로그래밍하는 것이 가능해질 것이라고 예견하였다.
이러한 견해는 인공지능(AI;Artificial Intelligence)의 개념적 기반을 제공하였으며, 그의 이름을 딴 '튜링 테스트'는 인공지능을 판별하는 기준이 되었다. 하지만 튜링은 포괄적 논리만 제시하였을 뿐 구체적인 실험 방법과 판별 기준을 제시한 것은 아니다. 현재 통용되는 테스트는 서로 보이지 않는 공간에서 질의자가 인간과 컴퓨터를 대상으로 정해진 시간 안에 대화를 나누는 방식으로 이루어지는데, 대화를 통하여 인간과 컴퓨터를 구별해내지 못하거나 컴퓨터를 인간으로 간주하게 된다면 해당 기계는 인간처럼 사고할 수 있는 것으로 본다.
2014년 6월 영국왕립학회가 실시한 튜링 테스트에서 영국의 레딩대학교가 개발한 컴퓨터 프로그램 '유진 구스트만(Eugene Goostman)'이 처음으로 테스트를 통과하였다. 이 테스트에서 우크라이나 국적의 13세 소년으로 설정된 '유진'과 대화를 나눈 심사위원 25명 가운데 33%가 진짜 인간이라고 판단하였다. 하지만 '유진'은 대화 도중에 엉뚱한 대답을 한 경우도 많아서 진정한 인공지능으로 인정하기 어렵다는 주장도 제기되었으며, 더 나아가 1950년에 제안된 오래된 개념의 '튜링 테스트'는 사람처럼 종합적으로 생각할 수 있는 진정한 인공지능을 판별하는 기준이 될 수 없다는 주장도 있다.
한편, 1990년 미국의 발명가 휴 뢰브너(Hugh Loebner)가 케임브리지행동연구센터(Cambridge Center for Behavioral Studies)와 공동으로 제정한 뢰브너상은 튜링 테스트를 기반으로 한다. 이 상은 해마다 튜링 테스트 경진대회를 개최하여 심사위원들이 '채팅 로봇(ChatBot)'이라는 채팅 프로그램과 대화를 나누는 방식으로 진행된다. 이 상을 제정하면서 인간과 구별할 수 없는 최초의 컴퓨터에 10만 달러의 상금과 금메달을 수여하기로 하였는데 여기에 해당되는 수상자는 아직 나오지 않았다. 대신 현재까지 매년 대회에 참가한 컴퓨터 중에서 가장 높은 점수를 받은 컴퓨터를 우승자로 선정하여 동메달과 상금 3000달러를 수여하고 있다.
[네이버 지식백과] 튜링 테스트 [Turing test] (두산백과)
생물학적 신경망
뉴런(neuron):: 뉴런의 기본 기능은 자극을 받았을 경우 전기를 발생시켜 다른 세포에 정보를 전달하는 것이다. 이렇게 발생하는 전기 신호를 활동전위(活動電位:action potential)라고 한다. 뉴런은 크게 세 가지 부분으로 나눌 수 있다. 핵이 있는 세포 부분이 신경세포체이며 다른 세포에서 신호를 받는 부분이 수상돌기(樹狀突起:dendrite), 그리고 다른 세포에 신호를 주는 부분이 축삭돌기(軸索突起:axon)이다. 돌기 사이에 신호를 전달하는 부분은 시냅스(synapse)라고 한다. 뉴런은 그 역할에 따라 감각뉴런, 연합뉴런, 운동뉴런의 세 종류로 나눌 수 있다. 또한 돌기가 몇 개 나와 있느냐에 따라, 즉 뉴런의 형태에 따라 종류를 나누기도 한다.
[네이버 지식백과] 뉴런 [neuron] (두산백과)
각 뉴런은 다른 많은 뉴런에 연결돼 있다. 뉴런은 이 연결을 거쳐 전기/화학 신호를 보낼 수 있다. 일부 연결은 다른 뉴런으로부터 신호를 받도록 설정돼 있고 나머지 연결은 다른 뉴런에 신호를 보낸다.

뉴런은 쉬고 있을 때 어떤 신호도 전송하지 않는다. 그러나 뉴런이 작동을 하면, 외부로 향한 모든 연결을 통해 빈번하게 신호를 보낸다.
일반적으로 들어오는 총 신호가 강하면 뉴런은 신호 전송을 시작하고, 그렇지 않으면 쉬는 상태를 유지한다. 다시 말해서 뉴런은 받는 모든 입력을 ‘더해’ 합이 충분히 큰 경우 신호를 보내기 시작한다. 실제로 흥분성(excitatory) 및 억제성(inhibitory)이라고 불리는 두 가지 유형의 입력이 있다. 흥분성 입력의 강도는 더하고 억제성 입력은 총합에서 뺀다. 따라서 억제성 입력이 강력하면 뉴런은 신호를 발사하지 못한다.
우산 문제에 대한 신경망
기본 모델에서 각 뉴런에 역치(threshold)라 불리는 수를 할당한다. 모델이 작동할 때 각 뉴런은 받는 입력을 더한다. 입력의 합이 역치에 이르면 뉴런은 신호를 쏘고 그렇지 않으면 쉬는 상태를 유지한다.

선글라스 문제에 대한 신경망


30x30 = 900 픽셀을 담고 있다. 그리고 세 개의 중앙 뉴런이 있으므로, 3x900 = 2700개의 연결이 이 신경망의 왼쪽 레이어에 있다.
신경망 구조의 선택은 대개 잘 작동하는 구조에 대한 과거 경험을 토대로 한다.
가중 신호 더하기
강화 1:신호는 0부터 1사이 값을 취할 수 있다. 완전히 흰 픽셀은 1의 값을 보내고 완전히 검은 픽셀은 0의 값을 보낸다. 다양한 회색 음영은 0과 1 사이의 값을 보낸다.
강화 2:총 입력은 가중 합계로 계산한다. 신경망은 모든 연결이 서로 다른 강도를 가질 수 있다는 점을 고려한다. 연결의 비중이라는 수가 연결의 강도를 반영한다. 비중은 양의 숫자일 수도 있고 음의 숫자일 수도 있다. 큰 양의 비중은 강한 흥분성 연결을 반영한다. 신호가 이런 연결을 거쳐 이동할 때 후속 뉴런은 신호를 쏠 가능성이 크다. 큰 음의 비중은 강한 억제성 연결을 반영한다. 이런 유형의 연결에서 신호는 후속 뉴런이 계속 쉬고 있는 상태로 머물게 한다. 뉴런이 이에 들어오는 입력의 총합을 계산할 때, 각 입력 신호에 이 연결의 비중을 곱한 다음 총합을 구한다. 그러므로 큰 비중은 작은 비중보다 더 큰 영향력을 가지며, 흥분성 및 억제성 신호가 상쇄될 수 도 있다.
강화 3:역치의 효과는 약화된다. 역치는 뉴런의 출력이 완전한 온on(즉 1)이나 완전한 오프off(즉 0)가 되도록 고정하지 않는다. 출력은 0에서 1 사이의 값이 될 수 있다. 총 입력이 역치보다 낮을 때 출력은 0에 가깝고 총 입력이 역치 이상일 때 출력은 1에 가깝다. 그러나 역치 부근의 총 입력은 0.5 근방의 중간 출력 값을 산출할 수 있다.

세 가지 강화 요소를 모두 가진 새로운 유형의 인공 뉴런을 보여 준다. 이 뉴런은 세 픽셀로부터 입력을 받는다. 이는 밝은 픽셀(신호 0.9), 중간 정도 밝기 픽셀(신호 0.6), 어두운 픽셀(신호 0.4)이다. 이 픽셀이 뉴런에 연결된 비중은 각각 10, 0.5, -3이다. 신호를 비중에 곱해 더하면 뉴런에 들어오는 총 신호 값은 8.1이 된다. 8.1은 2.5라는 뉴런의 역치보다 상당히 크므로 출력은 1에 매우 가깝다.
학습에 의한 신경망 조율
첫째, 모든 연결은 그 비중을 양(흥분성) 또는 음(억제성)이 될 수 있는 값으로 설정해야 한다(수천 개의 연결이 있을 수 있음을 기억하라). 둘째, 모든 뉴런에서 역치가 적합한 값으로 설정되게 해야 한다. 밝기 조절이 가능한 전등 스위치처럼 비중과 역치를 신경망의 작은 다이얼로 생각하면 좋다.
물론 이 다이얼을 손수 설정하려면 엄두를 내지 못할 정도로 시간이 많이 걸린다. 대신 학습 단계에서 컴퓨터를 이용해 다이얼을 설정할 수 있다. 처음에 다이얼은 무작위 값으로 설정된다. 그 다음에 컴퓨터에게 첫 훈련 샘플을 제시한다. 우리 예에서 이는 선글라스를 쓰거나 쓰지 않은 사람의 사진이다. 이 샘플은 신경망을 지나 0과 1 사이에서 하나의 출력값을 산출한다. 그러나 이 샘플은 훈련 샘플이므로 우리는 신경망이 이상적으로 산출해야 할 ‘목표’값을 알고 있다. 핵심 트릭은 출력값이 이상적인 목표값에 더 근접하도록 신경망을 조금 변경하는데 있다. 예를 들어 첫 훈련 샘플 사진에 선글라스가 있다고 가정하자. 그럼 목표값은 1이다. 그러므로 전체 신경망에 있는 모든 다이얼은 출력값이 1이라는 목표를 향해 움직이는 방향으로 조금씩 조정된다. 첫 훈련 샘플 사진에 선글라스가 없다면 모든 다이얼은 반대 방향으로 조금씩 움직여 출력값이 0을 향해 움직인다. 신경망은 차례대로 각 훈련 샘플을 받고, 신경망의 성능이 개선되도록 모든 다이얼이 조정된다. 모든 훈련 샘플을 여러 번 연습한 후 신경망은 성능 수준이 높아지고 학습 단계는 현재 다이얼 설정 상태에서 종료된다.
신경망 학습 단계는 신경망이 훈련 샘플에 대해 제대로 수행할 때까지 모든 비중과 역치를 반복 조정하는 일을 비롯해 상당한 작업량이 필요하다. 그러나 이 모든 것은 컴퓨터로 할 수 있으며, 새로운 샘플을 단순하고 효율적 방법으로 분류하는 데 이용할 수 있는 신경망이 결과로 산출된다.
학습단계가 완료되면 입력 이미지로부터 중앙 뉴런까지 수천 개의 연결 각각에 수치 비중(numerical weight)이 할당된다. 모든 픽셀로부터 하나의 뉴런으로만 가는 연결에 집중하면 이 비중을 이미지로 변환해 매우 편리하게 시각화할 수 있다.
한편, 이미지의 다른 부분에 이론적으로 선글라스의 존재 여부를 판단하는 데 전혀 영향을 주지 않는 강한 비중이 많이 있다는 점은 명확하다. 여기서 지난 수십 년간 인공지능 연구자들이 깨우친 가장 중요한 교훈의 하나를 접한다. 지적인 것처럼 보이는 행동이 무작위적 시스템에서 비롯됐을 수도 있다는 사실이다. 어떤 면에서는 전혀 놀랍지 않다. 인간 뇌로 들어가 뉴런 간의 연결 강도를 분석해 본다면 거의 대부분이 무작위로 나타날 것이다. 그러나 이 연결 강도의 허술한 집합이 총체적으로 작동할 때 인간의 지적 행동을 산출한다!
선글라스 신경망 활용
여기서 답을 골라내는 기술은 놀랍도록 간단하다. 0.5가 넘는 출력은 ‘선글라스 있음’으로, 0.5보다 작은 출력은 ‘선글라스 없음’으로 처리한다. 이 실험에서 선글라스 신경망의 최종 정확도는 약 85%로 나타났다.
패턴 인식:과거, 현재, 미래
1956년 다트머스대학교에서 열린 컨퍼런스에서 열 명의 과학자 그룹이 인공지능 분야를 확립하고 ‘인공지능’이라는 용어를 최초로 알렸다. 이 그룹의 주최자는 록펠러 재단에 보낸 컨퍼런스 연구비 지원 프로포절에서 ‘학습의 모든 측면이나 지능의 여타 특징은 이론상 매우 정확히 기술될 수 있어, 기계가 이를 시뮬레이션하게 만들 수 있다.’는 가설을 토대로 자신들의 연구가 진행될 것이라고 자신있게 기술했다.
1997년 IBM의 딥 블루(Deep Blue) 컴퓨터가 체스 세계 챔피언 게리 카스파로프를 이겼다.
7. 데이터 압축: 책 한 권을 종이 한 장에 담기
인터넷을 거쳐 전송되는 많은 메시지는 사용자조차 모르는 사이에 압축되고 거의 모든 소프트웨어는 압축된 형태로 다운로드된다. 이는 여러분의 다운로드와 파일 전송이 대개 압축 상태에서 그렇지 않은 상태보다 훨씬 더 빠르다는 뜻이다. 사람들이 수화기에 대고 말하는 목소리조차 압축된 채 전달된다. 목소리 데이터를 전송하기 전에 압축하면 전화 회사가 자원을 엄청나게 잘 활용할 수 있다.
무손실 압축:최고의 공짜 점심
무손실 압축 알고리즘은 데이터 파일을 취해 원래 사이즈의 일부로 압축한 다음 나중에 정확히 같은 원본파일로 압축을 푼다. 이와는 달리 손실 압축은 압축 해제 후 원본 파일에 약간 변화가 생긴다.
한 예로, 주 5일, 하루 8시간씩 일하고 일정을 한 시간 단위로 나눈다고 하자. 그래서 각 5일은 8개의 칸을 가지며 일주일에 총40개의 칸이 있다. 다시 말해서 여러분의 일정을 다른 사람에게 전하려면 40조각의 정보를 전해야 한다. 그러나 누군가가 다음 주 회의 일정을 잡으려고 여러분에게 연락한다면 여러분은 40개의 개별 정보 조각을 모두 열거해 시간이 있는지 여부를 설명하는가? 당연히 아니다! “월요일과 화요일은 꽉 찼고 목요일과 금요일엔 오후 1시에서 3시까지 선약이 있어요. 그 외 시간은 모두 가능합니다.” 이렇게 말할 가능성이 가장 크다. 이것이 무손실 데이터 압축의 예다! 여러분과 대화하는 사람은 다음 주 40시간 중 가능한 시간을 정확히 재구성할 수 있으며, 여러분은 이를 명시적으로 낱낱이 열거할 필요가 없다.
컴퓨터에서의 데이터 압축도 이런 방식으로 작동한다. 기본 개념은 서로 동일한 데이터의 부분을 찾아 일종의 트릭을 써서 더 효율적으로 기술하는 것이다.
AAAAAAAAAAAAAAAAAAAAABCBCBCBCBCBCBCBCBCBCAAAAAADEFDEFDEF
이 데이터를 읽어준다고 생각해 보라. “A, A, A, A, … , D, E, F”라고 말하는 대신 “21개의 A 다음에 10개의 BC, 다시 A 6개, 마지막으로 DEF 3개”라고 말하리라 확신한다. ‘21A, 10BC, 6A, 3DEF’라고 적을 수도 있다.
런-렝스 인코딩(run-length encoding) :: 동일 데이터가 자주 연속되는 경우, 데이터값과 연속되어 있는 길이만으로 정보를 표현하여 정보량을 줄이는 방식. 동일한 데이터가 연속되어 있는 것이 런(run)이며, 그 연속된 길이가 런 렝스(length)인데 이 데이터값과 그 길이만으로도 원래의 정보를 재현할 수 있다. 예를 들어, 'aaaaaaaaaaBcccccccccccccccccccc' 라는 정보는 'a'가 10개, 'B'가 1개, 'c'가 20개이므로 '10aB20c'로 짧게 표현해도 나중에 복원할 수 있다. 아이콘이나 그린 그림, 팩스 등의 그래픽 이미지는 동일 색의 연속이 많기 때문에 런 렝스 부호화(RLE)를 사용하면 정보량을 크게 줄일 수 있어 TIFF, BMP, PCX 등 파일 포맷에 사용되고 있다. RLE에는 변형 허프만 부호화 방식, 와일(whyle) 부호화 방식 등이 있다.
[네이버 지식백과] 런 렝스 부호화 [run length encoding, -符號化] (IT용어사전, 한국정보통신기술협회)
런-렝스 인코딩의 주요 문제점은 데이터에 있는 반복이 인접해 있어야 한다는 점이다. 다시 말해 반복 부분 사이에 다른 데이터가 있어서는 안 된다. ABABAB를 런-렝스 인코딩을 이용해 (3AB로) 압축하기는 쉽지만 ABXABYAB를 같은 트릭으로 압축하기란 불가능하다.
팩스는 검은색이나 흰색의 수많은 점으로 변환된 흑백 문서다. 여러분은 점을 순서대로 (왼쪽 위에서 오른쪽 아래로) 읽을 때 흰 점의 긴 런(배경)과 검은 점의 짧은 런(글)을 보게 된다. 이것이 런-렝스 인코딩을 효율적으로 사용할 수 있는 이유다.
‘전과 같음 트릭(same-asearlier trick)’ 과 ‘더 짧은 심벌 트릭(short-symbol trick)’ 두 가지만 다루겠다. ZIP 파일을 제작할 때 이 두 트릭만 이용하면 된다.
전과 같음 트릭
VJGDNQMYLH-KW-VJGDNQMYLH-ADXSGF-O-VJGDNQMYLH-ADXSGF-VJGDNQMYLH-EW-ADXSGF
전달해야 할 63개의 글자가 있다.(대시는 데이터를 읽기 편하게 하려고 삽입했기 때문에 무시한다.). 압축 알고리즘을 요약해 보자. ‘돌아가라(back).’는 말은 b로, ‘복사하라(copy).’라는 말은 c로 축약하겠다. 그러므로 “18자 돌아가서 6글자 복사하라.” 같은 ‘돌아가서 복사하라’는 지시는 b18c6로 축약한다.
VJGDNQMYLH-KW-b12c10-ADXSGF-O-b17c16-b16c10-EW-b18c6
이 문자열엔 44자만 있다. 원본엔 63자가 있었으므로 19자, 즉 원래 길이의 거의 3분의 1을 절약했다.
FG-FG-FG-FG-FG-FG-FG-FG
FG-FG-FG-FG-b8c8
FG-b2c14
압축된 메시지가 아닌 다시 생성된 메시지로부터 복사한다면 아무 문제도 발생하지 않는다. 이를 단계별로 해보자. 첫 두 글자를 받아쓰면 FG가 있다. 그리고 b2c14이란 지시가 오면 두 자 돌아가서 복사를 시작한다. 두 자(FG)만 복사할 수 있으므로 이를 복사하자. 우리가 이미 가진 글자에 이를 추가하면 FG-FG가 된다. 이제 두 글자를 더 복사할 수 있게 됐다! 그리고 이는 요구 글자수(이 경우 14글자)를 다 복사할 때까지 이어진다.
더 짧은 심벌 트릭


이는 A가 ‘1’이 아닌 ‘01’로 나타나는 정확한 이유다. 같은 이유에서 B는 ‘2’가 아닌 ‘02’로 나타나고, 이것은 I를 ‘9’가 아닌 ‘09’가 대표할 때까지 지속된다. A=‘1’, B=‘2’라고 하면 메시지를 명확히 해석하기란 불가능하다. 예를 들어 ‘1123’이라는 메시지는 (AAW로 번역되는) ‘1 123’으로 쪼갤 수도 있고 ‘11 2 3’(KBC)이나 ‘1 1 2 3’(AABC)으로도 나눌수 있다. 그러므로 서로 분리되지 않은 채 숫자 코드가 저장된 경우에도 숫자 코드와 글자 코드의 해석이 중의적이어서는 안 된다는 중요한 개념을 기억하라.
전과 같음 트릭에서 보았듯이 자주 쓰는 구문 또는 글자의 축약어를 쓰면 가장 많은 노력을 줄일 수 있다. ‘e’와 ‘t’sms 영어에서 가장 많이 쓰는 글자다. ‘e’는 8이, ‘t’는 9가 대표한다고 하자.

13889란 숫자를 디코딩하는 방법 하나는 이를 13-8-8-9로 찢어 ‘Meet’이란 단어를 만드는 것이다. 그러나 13-88-9로도 찢을 수 있다. 또 13-8-89가 될 수도 있다.
또 다른 트릭으로 이를 고칠 수 있다. 진짜 문제는 숫자 8 또는 9를 볼 때마다 이것이 한 자리 코드인지 8이나 9로 시작하는 두 자리 코드의 일부인지 구별할 방법이 없다는 점이다. 이 문제를 풀려면 희생을 해야 한다. 코드 일부는 실제로 더 길어진다. 애매한 8이나 9로 시작하는 두 자리 숫자 코드는 8이나 9로 시작하지 않는 세 자리 코드가 된다.

7로 시작하는 모든 코드는 세 자리 코드고, 8이나 9로 시작하는 모든 코드는 한 자리 코드이며 0, 1, 2, 3, 4, 5, 6 중 하나로 시작하는 모든 코드는 전과 같이 두 자리 숫자다. 그러므로 이제 13889를 찢는 방법은 하나밖에 없다(‘Meet’을 대표하는 13-8-8-9).
요약:공짜 점심은 어디서 올까?
단계 1. 압축되지 않은 원본 파일을 ‘전과 같음 트릭’을 이용해 변형해서 파일에 있는 반복 데이터 대부분을 돌아가서 데이터를 복사하라는 훨씬 짧은 지시로 교체한다.
단계 2. 변형된 파일에서 어떤 심벌이 자주 등장하는지 검토한다. 예를 들어 원본 파일이 영어라면 컴퓨터는 ‘e’와 ‘t’가 가장 흔한 심벌임을 발견하게 될 것이다. 그러면 컴퓨터는 자주 쓰는 심벌엔 짧은 숫자 코드를, 거의 쓰지 않는 심벌엔 긴 숫자 코드를 부여한 표를 구축한다.
단계 3.단계 2의 숫자 코드를 직접 번역해 다시 파일을 변형한다.

2단계에서 계산된 숫자 코드 테이블도 ZIP 파일에 저장된다. 실제 ZIP 파일의 숫자 코드 테이블은 각각 다르다.
손실 압축:공짜 점심은 아니지만 매우 좋은 거래
압축 파일을 원본과 매우 유사하지만 똑같지는 않은 파일로 재구성할 수 있게 하는 손실 압축을 이용하는 편이 훨씬 유용할 때도 있다. 예를 들어 손실 압축은 이미지나 오디오 데이터를 담은 파일에 흔히 쓴다. 사람이 눈으로 보기에 똑같아 보이는 이미지라면 컴퓨터에 저장하는 파일이 카메라에 저장한 파일과 똑같을 필요는 없다. 오디오 데이터도 마찬가지다. 사람 귀에 똑같이 들리기만 하면 디지털 뮤직 플레이어에 저장한 노래 파일과 CD에 저장한 노래 파일이 정확히 같을 필요는 없다.
생략 트릭
사진은 ‘픽셀’이라고 부르는 수많은 작은 점으로 구성된다. 각 픽셀은 정확히 한 색을 가지며 이는 검은색이나 흰색, 회색 음영일 수 있다.
컴퓨터에 저장된 흑백 사진에서 각 픽셀 컬러는 숫자로 대표된다. 예를 들어 숫자가 크면 흰색에 가깝다. 100이 가장 흰색이라고 한다면, 0은 검은색을 대표하고, 50은 중간 회색 음영을, 90은 밝은 회색을 대표한다.
파일을 아주 단순한 기법으로 압축할 수 있다. 이는 짝수 번째 열과 행을 무시하거나 ‘생략하는’ 방법이다. 폭과 높이를 모두 반으로 줄여 전체 픽셀의 수를 4분의 1로 줄이면 파일의 크기는 원본 파일의 4분의 1에 불과하다. 실제로 이미지의 크기는 50%씩 (수직으로 한 번, 수평으로 한 번) 두 번 줄었고 이는 원본의 25%에 불과한 크기가 되었다.
픽셀의 열과 행 중 일부가 삭제됐기에 컴퓨터는 이 사라진 픽셀의 색을 추측해야 한다. 가장 단순한 추측은 근처 픽셀 중 아무 픽셀과 같은 색을 부여하는 방법이다. 시각적 특징 대부분이 유지되지만 품질과 세부 묘사에서 명확한 손실이 있다. 이를 ‘압축 가공물(compression artifact)’이라고 부른다. 이는 단지 세부 항목의 손실이 아니라 압축 해제 후 특정 손실 압축 방법으로 인한 눈에 띄는 새로운 특징을 말한다.
컴퓨터는 실제로 정보를 ‘생략해’ 손실 압축을 하지만, 생략할 정보를 훨씬 주의 깊게 선택한다. 이 기법의 흔한 예로는 JPEG이미지 압축 포맷을 들 수 있다. JPEG는 세심하게 고안한 이미지 압축 기법으로 짝수 번째 열과 행을 생략하는 방법보다 훨씬 나은 성과를 보여 준다.
이 기법의 기본 발상은 상당히 간단하다. JPEG는 우선 전체 이미지를 8×8픽셀 크기의 작은 정사각형으로 나눈다. 각 정사각형을 개별적으로 압축한다. 압축하지 않으면 각 사각형을 8×8 =64개의 수가 대표한다는 점을 주목하라(우리는 흑백 사진이라고 가정한다. 컬러 이미지일 경우 세 가지 서로 다른 색이 있고 따라서 수는 세 배가 된다. 그렇기 때문에 여기서 이런 세부 내용을 신경 쓰지 않겠다). 우연히 정사각형 안에 있는 색이 모두 같다면 단 하나의 수가 이 사각형 전체를 대표할 수 있고 컴퓨터는 63개의 수를 ‘생략할’ 수 있다. (예컨대 거의 같은 회색 음영인 하늘 지역처럼) 정사각형이 약간의 차이만 있고 거의 동일한 색이라면 컴퓨터는 하나의 숫자로 대체할 수 있고, 압축을 해제했을 때 매우 작은 오류만이 드러나는 괜찮은 압축 결과를 낳는다.
8×8 정사각형이 한 색에서 다른 색으로(예컨대 왼쪽의 어두운 회색에서 오른쪽의 밝은 회색으로) 점차 변한다면 64개의 수를 두 수로 압축할 수 있다. 하나는 어두운 회색을 대표하는 값이고 다른 하나는 밝은 회색을 대표하는 값이다. JPEG 알고리즘이 정확히 이렇게 작동하진 않지만 유사한 아이디어를 기반으로 한다. 8×8 정사각형이 단색이나 그라디언트처럼 이미 알려진 패턴의 조합에 충분히 가깝다면 정보 대부분을 버릴 수 있고 각 패턴의 수준이나 양만 저장하면 된다.
MP3와 AAC 같은 흔한 음악 압축 포맷은 일반적으로 JPEG 같은 고도의 접근을 이용한다. JPEG와 마찬가지로 예측 가능한 방식으로 변하는 청크는 몇 개의 수만으로 기술할 수 있다. 그러나 오디오 압축 포맷은 인간 귀에 관한 사실도 이용할 수 있다. 특히 특정 유형의 소리는 인간에게 거의 또는 전혀 영향을 주지 않고, 압축 알고리즘으로 산출물의 품질을 떨어뜨리지 않으면서도 이를 제거할 수 있다.
압축 알고리즘의 기원
사실 오류 정정 코드와 압축 알고리즘은 동전의 양면과 같다. 이는 모두 앞장에서 꽤 많이 다룬 리던던시(redundancy)라는 개념으로 압축된다. 파일이 리던던시를 가지면 이는 필요 이상으로 길어진다. 파일은 숫자 ‘5’ 대신 ‘five’라는 단어를 쓸 수도 있다. 이런 식으로 ‘fivq’ 같은 오류를 쉽게 인식해 정정할 수 있다. 그러므로 오류 정정 코드를 메시지나 파일에 리던던시를 더하는 원칙에 입각한 방식으로 볼 수 있다.
압축 알고리즘은 정반대의 작업을 한다. 이는 메시지나 파일에서 리던던시를 제거한다. 오류 정정 인코딩 과정과는 정반대로 파일에서 'five’란 단어가 자주 사용되고 있음을 알아채고 이를 (‘5’란 심벌보다도 더 짧을 수도 있는) 더 짧은 심벌로 교체하는 압축 알고리즘을 상상하면 된다. 실제로 압축과 오류 정정이 이엃게 서로 상쇄하지는 않는다. 대신 좋은 압축 알고리즘은 비효율적 유형의 리던던시를 제거하고 오류 정정 인코딩은 이와 다른 더 효율적 유형의 리던던시를 더한다. 그러므로 메시지를 먼저 압축한 뒤 오류 정정 코드를 더하는 일이 일반적이다.
허프만 코딩 :: 허프만 부호를 구성하는 방식. 허프만 부호를 구성할 때의 순서는 다음과 같다. ㉠발생 확률이 가장 낮은 2개의 기호를 선정한다. ㉡㉠에서 선정한 2개의 기호를 합해서 하나의 새로운 기호로 하고, 발생 확률은 그 둘의 합으로 한다(전체 기호 수가 하나 감소된다). ㉢기호 수가 1이 될 때까지 ㉠과 ㉡의 조작을 반복한다. ㉣하나가 된 기호로부터, 기호 수가 2개였던 상태로 거슬러 올라가서 분기된 2개의 기호에 0 또는 1을 할당한다. ㉤기호를 감소해 나간 조작을 거슬러 올라가서 0 또는 1을 이때까지 할당되어 있는 부호의 뒤에 놓아, 그 기호의 부호어로 한다. ㉥기호 수가 원래의 수가 될 때까지 ㉤의 조작을 반복한다. 예로서, 아래의 표와 같이 발생 확률에 제시되어 있는 차분 펄스 부호 변조(DPCM)의 예측 오차 신호에 대한 허프만 부호를 위와 같은 순서로 구성하면, 구성된 허프만 부호의 길이는 2.14비트로 엔트로피에 가장 가까운 값이 된다.
[네이버 지식백과] 허프만 부호화 방식 [Huffman encoding, -符號化方式] (IT용어사전, 한국정보통신기술협회)
8. 데이터베이스: 일관성을 향한 여정
데이터베이스는 거래 과정에서 두 가지 주요 사안을 처리한다. 이는 효율성과 신뢰성이다. 데이터베이스는 수천 명의 고객이 충돌이나 모순 없이 동시에 거래를 수행하게 하는 알고리즘을 기반으로 효율성을 제공한다.
커밋(commit): 데이터베이스 트랜잭션에서 커밋은 갱신 내용을 실제로 수행하고 트랜잭션을 종료하라는 명령이다.
구조화되지 않은 정보의 예
로시나는 35세고 26세인 맷과 친구다. 징이는 37세고 수딥은 31세다. 맷과 징이, 수딥은 서로 친구다.
구조화된 양식

이런 유형의 구조를 테이블(table)이라고 부른다. 테이블의 각 행은 하나의 대상(이 예에선 사람)에 관한 정보를 담고 있다. 테이블의 각 열은 사람의 나이나 이름 같은 특정 유형의 정보를 담고 있다. 데이터베이스는 대개 여러 테이블로 구성된다.
데이터베이스 실무자들은 (합당한 이유에서) 일관성에 집착한다. 간단히 말해 ‘일관성’은 데이터베이스에 있는 정보가 모순되지 않음을 뜻한다.
데이터베이스에 새로운 데이터를 추가할 때 불일치는 쉽게 피할 수 있다. 컴퓨터는 규칙을 따르는 데 탁월하므로 ‘A가 B와 결혼했다면 B도 A와 결혼했어야 한다.’라는 규칙을 따르도록 데이터베이스를 설정하기란 쉽다. 누군가 이 규칙을 위반하는 새로운 행을 입력하려 하면 컴퓨터는 오류 메시지를 띄우고 입력은 실패한다.
트랜잭션과 할 일 목록 트릭
트랜잭션(Transaction) :: 디지털 교환처리는 다수의 호에 대한 처리를 동시에 병행하는 다중처리 방식이 취해지고 있다. 트랜잭션은 각각의 호에 관한 처리가 간섭하는 경우가 없는 호(呼)에 관한 제어정보를 저장하기 위하여 호에 대응하여 설계된 메모리 에어리어에서 각 처리간의 제어정보 접수를 관리한다.
이 트랜잭션은 호량(呼量)에 따라 설비되고, 호의 발생 때마다 필요한 수가 사용되며, 처리종료 후에는 다시 공백 상태로 되돌아가서 다른 호(呼)에 의하여 사용할 수 있게 되며, 이 트랜잭션은 제어정보를 세트(set)시킨 상태로 대기행렬(queue)에 등록되어 실행에 응하게 된다. 그림은 처리의 흐름과 트랜잭션과의 관계를 도시한 것이다.
[네이버 지식백과] 트랜잭션 [Transaction] (정보통신용어사전, 2008.1.15., 일진사)
트랜잭션의 정의와 필요성을 이해하려면 컴퓨터에 관한 두 가지 사실을 받아들여야 한다. 첫 번째는 프로그램이 충돌한다는 점이다. 그리고 프로그램이 충돌하면, 기존에 하던 모든 일을 잊는다. 컴퓨터 파일 시스템에 직접 저장한 정보만 보존된다. 두 번째 사실은 하드 드라이브와 플래시 메모리 스틱 같은 컴퓨터 저장 장치는 적은 양의 데이터만을 동시에 쓸 수 있다는 점이다. 이는 약 500자 정도에 해당한다(일반적으로 512바이트인 하드 디스크의 ‘섹터 크기’에 해당하며, 플래시 메모리에서는 수백 또는 수천 바이트의 ‘페이지 크기’에 해당한다). 오늘날 드라이브가 이런 500자 쓰기를 1초에 수백, 수천 번 실행할 수 있기 때문에 컴퓨터 사용자는 한 번에 저장하는 데이터의 양에 이렇게 작은 크기의 제한이 있다는 사실을 눈치채지 못한다.
일반적으로 컴퓨터는 한 번에 데이터베이스의 한 행만을 업데이트할 수 있다. 일반적인 크기의 데이터베이스에서 두 행을 바꾸려면 각각 두 번의 디스크 연산이 필요하다.
겉보기에 간단해 보이는 많은 데이터베이스 변화는 두 행 이상의 변화를 요한다. 그리고 방금 설명했듯 두 행의 변화를 한 번의 디스크 작업으로 달성할 순 없다. 그래서 데이터베이스 업데이트는 두 번 이상의 연속적인 디스크 작업을 초래한다. 그러나 컴퓨터는 언제든 충돌할 수 있다. 두 번의 디스크 작업 사이에 컴퓨터가 충돌하면 어떻게 될까? 컴퓨터를 재부팅할 수 있지만 컴퓨터는 수행하려 했던 모든 작업을 잊어버린다. 따라서 필수적인 변화가 일부 이뤄지지 않았을 수 있다.
일부 운영체제는 충돌 후 재부팅할 때 전체 파일 시스템의 불일치를 점검한다.
당좌예금 :: 은행의 요구불예금(要求拂預金)의 하나이다. 이 경우 발행된 수표는 현금과 같은 기능을 가지므로 예금통화(預金通貨)로 유통된다. 금전의 수불(受拂)이 빈번한 기업이 현금의 보관이나 출납(出納)의 번거로움과 위험성을 은행에 맡기기 위하여 이용된다. 그러나 개설하는 데는 딴 예금과 달리 특별한 계약이 필요하다. 은행으로서는 취급이 번거로우며 정착성(定着性) 예금과는 달리 자금운용도 제약되므로 이자가 없으나, 거래자는 당좌대월(當座貸越) 계약에 의하여, 예금잔고 이상으로 발행한 수표에 대해서도 지불을 받을 수 있는 편리한 점도 있다.
[네이버 지식백과] 당좌예금 [checking accounts, 當座預金] (두산백과)
트랜잭션은 데이터베이스가 일관적인 경우 모두 일어나야 하는 데이터베이스 변화의 집합이다. 전체가 아닌 일부의 변화가 트랜잭션에서 수행된다면 데이터베이스는 불일치 상태로 남을 수 있다. 이는 간단하지만 매우 강력한 개념이다. 데이터베이스 프로그래머는 “트랜잭션을 시작하라.” 같은 명령을 발행하고 데이터베이스에 상호의존적인 변화들을 가한 다음 “트랜잭션을 종료하라.”라는 명령으로 마무리할 수 있다. 트랜잭션 중 데이터베이스를 실행 중인 컴퓨터가 충돌을 일으켜 재시작된 경우에도 데이터베이스는 프로그래머의 변화를 모두 성취하게 된다.
충돌 및 재시작 후 데이터베이스가 트랜잭션 시작 전과 같은 상태로 돌아갈 수 있다. 그러나 이런 일이 일어날 경우 프로그래머는 트랜잭션이 실패했으므로 재실행해야 한다는 공지를 받게 된다. 그러므로 피해는 발생하지 않는다. 데이터베이스는 트랜잭션이 완료되든 복귀되든 상관없이 일관성을 유지한다.
할 일 목록 트릭
미리 쓰기 로그(write-ahead logging) :: 로그 선행 기입(write-ahead logging, WAL)은 데이터베이스 시스템에서 ACID의 특성 가운데 원자성과 내구성을 제공하는 기술의 한 계열이다.
WAL을 사용하는 시스템에서 모든 수정은 적용 이전에 로그에 기록된다. 일반적으로 redo 및 undo 정보는 둘 다 로그에 저장된다.
한 예로 어느 프로그램이 특정 작업을 수행하는 동안 컴퓨터에 정전이 일어났다고 하자. 다시 시작할 때 프로그램은 어느 작업이 수행을 성공적으로 마쳤는지, 절반 성공했는지, 아니면 실패했는지를 잘 알고 있어야 한다. 로그 선행 기입이 사용된다면 프로그램은 이러한 로그를 검사하여 예기치 않은 정전 시 해야할 일과 실제로 했던 일을 비교하게 된다.
WAL은 데이터베이스 업데이트가 인 플레이스 알고리즘을 사용할 수 있게 한다. 원자적 업데이트를 구현하는 또다른 방법은 인 플레이스 알고리즘이 아닌 그림자 페이징 기법을 사용하는 것이다. 인 플레이스로 업데이트할 때의 주된 이점은 색인과 블록 목록의 수정 필요성을 줄인다는 점이다.
ARIES는 WAL 계열 중 잘 알려진 알고리즘이다.
[위키백과] 로그 선행 기입(write-ahead logging, WAL)
기본 개념은 데이터베이스가 수행하려는 동작의 로그를 유지하는 것이다. 로그는 하드 드라이브 같은 영구적 저장 장치에 저장된다. 그래서 로그에 있는 정보는 충돌과 재시작 후에도 살아남게 된다. 특정 트랜잭션에서 동작이 수행되기 전에, 모든 동작은 로그에 기록되고 디스크에 저장된다. 트랜잭션이 성공적으로 완료되면 우리는 로그에서 트랜잭션의 할 일 목록을 삭제해 디스크 공간을 늘릴 수 있다.
우선 데이터베이스 테이블은 건드리지 않고 트랜잭션의 할 일 목록을 로그에 쓴다.

로그 엔트리를 디스크 같은 영구 저장 장치에 확실히 저장한 다음 테이블 자체에 계획한 변화를 준다. 테이블의 변화가 디스크에 저장되면 로그 엔트리를 삭제할 수 있다. 이제 로그에 정보가 남아 있으므로, 컴퓨터는 충돌이 일어났을 때 트랜잭션 도중이었음을 알 수 있다.
멱등 (idempotent) :: 멱등법칙 또는 멱등성(idempotence)은 수학이나 전산학에서 연산의 한 성질을 나타내는 것으로써, 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 의미한다. 멱등법칙의 개념은 추상대수학(특히, 투영 이론·닫힘 연산·함수형 프로그래밍의 참조 투명성과 연관된 성질에서)의 여러 부분에서 사용하고 있다.
[위키백과] 멱등법칙
데이터베이스가 충돌 후 복구한 다음 로그에서 엔트리를 보면 이를 충돌 전에도 수행했는지 걱정하지 않고 안전하게 수행할 수 있다. 그러므로 데이터베이스는 충돌로부터 복구한 다음 이미 완료된 트랜잭션의 로그 동작을 다시 할 수 있다. 그리고 완료되지 않은 트랜잭션도 처리하기 쉽다. ‘트랜잭션 종료’라는 엔트리로 마무리되지 않은 모든 로그 동작은 역순으로 원상태로 복원돼 트랜잭션이 시작되지 않은 데이터베이스 상태로 돌아간다.
크고 작은 원자성
데이터베이스 사용자의 관점에서 모든 트랜잭션은 원자성(atomicity)을 띤다. ‘원자적(atomic)’이라는 단어는 ‘쪼갤 수 없는’이란 뜻의 그리스어에서 유래했다. 수십 년 전 물리학자들에 의해 원자도 분리할 수 있음이 밝혀졌지만, 컴퓨터과학자들이 ‘원자적’이라고 말할 때 이는 쪼갤 수 없다는 원래 뜻을 지칭한다. 따라서 원자적 트랜잭션은 더 작은 작업으로 쪼갤 수 없다. 즉 트랜잭션 전체가 성공적으로 완료되거나 데이터베이스는 트랜잭션이 시작조차 되지 않은 원래 상태로 남아 있어야 한다.
할 일 목록 트릭은 불일치를 예방하므로 신뢰성의 좋은 척도이기도 하다. 구체적으로 말하자면 할 일 목록 트릭은 데이터 오염을 사전에 차단하지만 데이터 손실을 제거하진 못한다.
중복 데이터베이스를 위한 준비 후 커밋 트릭
‘준비 후 커밋’을 이해하려면 데이터베이스에 관한 두 가지 이상의 사실을 이해해야 한다.
첫째, 데이터베이스는 복제될 수 있다. 이는 서로 다른 장소에 복수의 데이터베이스 사본을 저장할 수 있다는 뜻이다. 둘째, 때론 데이터베이스 트랜잭션이 취소돼야 한다. 이를 트랜잭션 ‘복귀’ 또는 ‘중단’이라고도 부른다.
중복 데이터베이스
데이터베이스는 할 일 목록 트릭 덕분에 충돌 시점에 진행 중이던 트랜잭션을 완료하거나 복귀시켜 특정 유형의 충돌을 회복시킬 수 있다. 그러나 이는 충돌 전 저장된 모든 데이터가 여전히 그대로 남아 있을 경우를 상정한다. 컴퓨터의 하드 드라이브가 다시 쓸 수 없게 망가져서 데이터의 일부 또는 전체가 손실됐다면 어떻게 해야 할까?
널리 이용되는 해결책은 두 개 이상의 데이터베이스 사본 유지다. 데이터베이스의 사본 하나를 복제본(replica)이라 부르고 모든 사본의 집합을 중복 데이터베이스(replicated database)라 칭한다.
중복 데이터베이스는 데이터의 ‘백업(backup)’ 유지라는 친숙한 개념과 조금은 다르게 작동한다는 점을 주의하라. 백업은 특정 시점 데이터의 스냅샷이다. 수동 백업을 하는 경우 백업 프로그램을 실행할 때 스냅샷을 찍는 반면, 자동 백업은 매일 오전 2시처럼 주 또는 하루 단위로 특정 시점에 시스템의 스냅샷을 찍는다. 다시 말해 백업은 파일이나 데이터베이스 등 여분의 사본이 필요한 모든 정보의 완벽한 사본(duplicate)이다.
그러나 백업은 반드시 최신 상태를 유지하진 않는다. 백업 이후 변화가 발생하면 이 변화는 다른 장소에 저장되지 않는다. 이와 달리 중복 데이터베이스는 데이터베이스의 모든 사본을 늘 동기화한다. 데이터베이스의 어떤 엔트리에라도 아주 작은 변화가 있을 때마다 모든 복제본은 즉시 같은 변화를 반영해야 한다.
트랜잭션 복귀
트랜잭션은 데이터베이스의 일관성을 보장하기 위해 반드시 수반되어야 하는 데이터베이스에 대한 일련의 처리 동작이다. 어떤 이유에서 트랜잭션을 완료할 수 없을 때도 있다. 예를 들어 트랜잭션은 데이터베이스에 많은 양의 데이터를 추가하므로 트랜잭션 도중 컴퓨터의 디스크 공간이 부족할 수 있다.
훨씬 흔한 트랜잭션 완료 실패의 이유는 잠금(lock)이라는 데이터베이스 개념과 관련된다. 바쁜 데이터베이스에선 대개 동시에 실행 중인 트랜잭션이 많다(은행이 한 번에 한 고객만 이체할 수 있게 한다면 어떤 일이 벌어질지 생각해 보라. 이런 온라인 뱅킹 시스템의 성능은 정말로 끔찍하다). 그러나 데이터베이스의 일부는 트랜잭션 중에 그대로 유지돼야한다. 예를 들어 트랜잭션 A가 로시나가 징이의 친구가 됐다고 기록하는 엔트리를 업데이트하는 동시에 실행 중인 트랜잭션 B가 데이터베이스에서 징이를 삭제한다면 끔찍한 결과가 초래된다. 그러므로 트랜잭션 A는 징이의 정보를 담고 있는 데이터베이스의 부분을 ‘잠근다’. 이는 데이터가 그대로 고정돼 있고 어떤 다른 트랜잭션도 이를 바꿀 수 없다는 뜻이다. 대부분 데이터베이스에서 트랜잭션은 개별 행이나 열 또는 테이블 전체를 잠근다. 한 번에 한 트랜잭션만 데이터베이스의 특정 부분을 잠글 수 있다는 점은 분명하다. 트랜잭션이 성공적으로 완료되면 잠가놨던 모든 데이터가 ‘열리고’ 이 시점 이후로 다른 트랜잭션은 고정되었던 데이터를 자유롭게 바꿀 수 있다.

핵심은 트랜잭션은 예상치 못한 이유로 완료되지 않을 때가 많다는 사실이다.
할 일 목록을 약간 변형하면 복귀를 달성할 수 있다. 이는 미리 쓰기 로그가 필요한 경우 각 작업을 원상복귀할 추가 정보를 담고 있어야 한다는 것이다(이는 각 로그 엔트리가 충돌 후 작업을 다시 할 정보를 담고 있어야 한다는 점을 강조한 앞선 설명과 대조된다). 취소 정보와 재개 정보는 똑같다. ‘제이디의 당좌예금 계좌 잔액을 $800에서 $600로 변경’ 같은 엔트리는 (제이디의 당좌예금 계좌 잔액을 $600에서 $800로 바꿔서) 쉽게 ‘취소’될 수 있다. 요컨대 트랜잭션이 복귀돼야 한다면, 데이터베이스 프로그램은 미리쓰기 로그(즉 할 일 목록)를 통해 트랜잭션에 있는 작업을 역순으로 되돌릴 수 있다.
준비 후 커밋 트릭
중복 데이터베이스에서 트랜잭션 복귀 문제를 생각해 보자. 여기서 중요한 사안은 복제본 중 하나가 다른 복제본에선 발생하지 않은 복귀를 요하는 문제에 당면할 수 있다는 점이다. 다른 복제본의 디스크 공간은 충분하지만 한 복제본만 디스크 공간이 부족한 상황을 생각해 볼 수 있다.
당신과 세 친구가 최근 개봉한 영화를 함께 보고 싶어 한다고 하자. 당신이 가능하고 (당신이 아는 한) 친구들에게도 적합할 듯한 영화 시간을 결정한다. 당신이 화요일 8시를 선택했다고 하자. 다음 단계엔 친구 중 한 명에게 전화해 화요일 8시가 괜찮은지 물어야 한다. 친구가 괜찮다고 하면 당신은 “좋아! 일단 그때 영화를 보기로 하고 나중에 확실히 정해서 전화해 줄게.”라고 말한다. 그 다음에 당신은 또 다른 친구에게 전화해서 같은 일을 한다. 마지막으로 세 번째 친구에게 같은 제안을 한다. 화요일 8시가 모두 괜찮다면, 당신은 일정을 확정하고 친구들에게 다시 전화를 해 이를 알린다.
한 친구가 화요일 8시는 어렵다면 어떨까? 이 경우 당신은 지금까지 진행한 작업을 모두 ‘복귀’시키고 재시작해야 한다. 현실에서 당신은 각 친구에게 전화를 해서 즉시 새로운 시간을 제안할 것이다. 그러나 여기선 예를 최대한 단순화하고자 당신이 각 친구에게 전화를 해 “미안하지만 화요일 8시는 안 돌 듯하니 달력에서 이 약속을 지워라. 곧 새로운 약속 시간을 정해서 다시 전화할게.”라고 말한다고 하자. 이렇게 하고나면 당신은 모든 절차를 처음부터 다시 시작할 수 있다.
영화 관람 약속을 잡는 전략에 두 단계가 있음을 주목하라. 우선 날자와 시간을 제안하지만 이는 100% 확실하진 않다. 당신은 모두로부터 해당 날짜와 시간이 가능하다는 회신을 받으면, 이 날짜와 시간은 이제 100% 확실하다는 점을 알게 되지만, 다른 친구는 아직 모른다. 그러므로 약속을 확정하는 전화를 친구들에게 다시 하는 두 번째 단계가 있다. 또는 한 명 이상의 친구가 이 약속 시간을 맞출 수 없다면 두 번째 단계는 기존 약속을 취소하는 통화가 된다. 컴퓨터과학자들은 이 ‘준비 후 커밋 트릭(prepare-then-commit trick)’을 2단계 커밋 프로토콜이라 부른다.
2단계 커밋 프로토콜 :: 트랜잭션 처리, 데이터베이스, 컴퓨터 네트워크에서 2단계 커밋 프로토콜(two-phase commit protocol, 2PC)은 원자적 커밋 프로토콜(ACP)의 일종이다. 트랜잭션을 커밋할지, 아니면 롤백할지에 대해 분산 원자적 트랜잭션에 관여하는 분산 알고리즘의 하나이다. (특별한 종류의 일치 프로토콜) 이 프로토콜은 수많은 종류의 일시적 시스템 문제(프로세스, 네트워크 노드, 통신 등)에도 목표를 수행하므로 널리 이용된다. 그러나 잠재적인 모든 문제 구성을 복구할 수 있는 것은 아니며, 드문 경우 문제 해결을 위해 사용자(시스템의 관리자)의 간섭이 요구된다.
[위키백과] 2단계 커밋 프로토콜
첫 단계는 ‘준비’ 단계다. 두 번째 단계는 최초 제안을 모두가 수용했는지 여부에 따라 ‘결정’ 또는 ‘중단’ 단계가 된다.
흥미롭게도 이 비유에는 데이터베이스 잠금 개념이 있다. 명시적으로 논하진 않았지만 각 친구는 영화 관람 약속을 일단 예정할 때 암묵적으로 화요일 8시에 다른 일정을 잡지 않기로 약속한 셈이다. 당신으로부터 이들이 확정 또는 취소 전화를 다시 받을 때까지 달력에서 이 칸은 ‘잠기고’ 다른 ‘트랜잭션’이 이를 변경할 수 없다. 예를 들어 첫 단계와 둘째 단계 사이에 다른 사람이 당신의 친구에게 전화해서 화요일 8시에 농구 경기를 보러 가자고 제안한다면 어떤 일이 일어날까? 당신의 친구는 “미안하지만 그 시간엔 다른 약속이 잡혀 있어. 약속이 확정되기 전엔 농구 경기 관람에 대한 확답을 줄 수 없어.” 같은 말을 해야 한다.


관계형 데이터베이스와 가상 테이블 트릭
오늘날 데이터베이스 테크놀로지의 진짜 힘은 복수의 테이블을 가진 데이터베이스에서 촉발됐다. 기본 아이디어는 각 테이블이 서로 다른 정보의 집합을 저장하지만 다양한 테이블에 있는 대다수 개체는 어떤 식으로든 서로 연결된다는 것이다. 그래서 회사 데이터베이스는 고객 정보, 공급자 정보, 제품 정보 각각에 대한 개별 테이블로 구성될 수 있다.

복수 테이블 접근의 이점 하나를 즉시 알 수 있다. 즉 저장해야 하는 정보의 양이 줄어든다. 이 새로운 접근은 10행과 2열짜리(10×2=20항목) 테이블 하나와 3행과 4열짜리(3×4=12항목) 테이블 두 개를 이용하며 따라서 총 32항목을 저장한다. 이와 달리 단일 테이블 접근은 똑같은 정보를 저장하는 데 50항목을 필요로 했다. 어떻게 이렇게 간추릴 수 있었을까? 이는 반복되는 정보를 제거했기 때문이다.
복수 테이블 접근엔 또 다른 큰 장점이 있다. 테이블을 정확히 설계한다면 데이터베이스에 쉽게 변화를 줄 수 있다. 예를 들어 MATH314의 강의실 번호가 560에서 440으로 바뀌었다고 하자. 단일 테이블 접근에서는 네 개의 개별 행을 업데이트해야한다. 그리고 앞서 언급했듯 데이터베이스 일관성을 유지하려면 한 번에 트랜잭션에서 네 개의 업데이트를 끝내야 할 것이다. 그러나 복수테이블 접근에선 강의 상세 정보에 관한 테이블에서 단 하나의 엔트리만 업데이트하면 된다.
키
테이블에 있는 상세 정보를 ‘찾아보는’ 데 이용하는 열을 데이터베이스 용어로 키(key)라고 한다.

빠르게 키를 찾고자 사전에 계산된 묶음의 집합을 컴퓨터과학에선 B-트리(B-tree)라 한다.
B-트리 :: 전산학에서 B-트리(B-tree)는 데이터베이스와 파일 시스템에서 널리 사용되는 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다.
방대한 양의 저장된 자료를 검색해야 하는 경우 검색어와 자료를 일일이 비교하는 방식은 비효율적이다. B-트리는 자료를 정렬된 상태로 보관하고, 삽입 및 삭제를 대수 시간으로 할 수 있다. 대부분의 이진 트리는 항목이 삽입될 때 하향식으로 구성되는 데 반해, B-트리는 일반적으로 상향식으로 구성된다.
n개의 키 (s1,s2,s3...,sn)가 있는 한 노드를 생각해 보자. 키집합은 정열되어 있다고 한다. (즉, s1<s2<s3...<sn) 그 노드는 n+1자식노드를 가리키는 포인터로 구성된다. 즉, t0,t1,t2...tn.
B-트리의 기본 개념은 내부 노드의 자식 노드의 수가 미리 정해진 범위 내에서 변경가능하다는 것이다. 항목이 삽입되거나 삭제될 때, 내부 노드는 해당 범위의 자식 노드의 수를 만족시키기 위해 분리되거나 혹은 다른 노드와 합쳐지게 된다. 자식 노드의 수가 일정 범위 내에서만 유지되면 되므로 분리 및 합침을 통한 재균형 과정은 다른 자가 균형 이진 탐색 트리만큼 자주 일어나지 않지만, 저장 공간에서의 손실은 있게 된다. 자식 노드의 최소 및 최대수는 일반적으로 특별한 구현에 대해서 결정되어 있다. 예를 들어, 2-3 B-트리(혹은 단순히 2-3 트리)에서 각 내부 노드는 2 또는 3개의 자식 노드를 가질 수 있다. 만약 허용되지 않은 수의 자식 노드를 가질 경우, 해당 내부 노드는 부적절한 상태에 있다고 한다.
B-트리는 노드 접근시간이 노드에서의 연산시간에 비해 훨씬 길 경우, 다른 구현 방식에 비해 상당한 이점을 가지고 있다. 이는 대부분의 노드가 하드디스크와 같은 2차 저장장치에 있을 때 일반적으로 일어난다. 각 내부 노드에 있는 자식 노드의 수를 최대화함으로써, 트리의 높이는 감소하며, 균형맞춤은 덜 일어나고, 효율은 증가하게 된다. 대개 이 값은 각 노드가 완전한 하나의 디스크 블록 혹은 2차 저장장치에서의 유사한 크기를 차지하도록 정해진다.
B-트리의 창시자인 루돌프 바이어는 'B'가 무엇을 의미하는지 따로 언급하지는 않았다. 가장 가능성 있는 대답은 리프 노드를 같은 높이에서 유지시켜주므로 균형잡혀있다(balanced)는 뜻에서의 'B'라는 것이다. '바이어(Bayer)'의 'B'를 나타낸다는 의견도, 혹은 그가 일했던 보잉 과학 연구소(Boeing Scientific Research Labs)에서의 'B'를 나타낸다는 의견도 있다.
[위키백과] B-트리
가상 테이블 트릭
데이터베이스의 모든 정보는 고정된 테이블에 저장되지만 데이터베이스는 필요할 때마다 완전히 새로운 테이블을 일시적으로 생성할 수 있다. 이렇게 일시적으로 추가하는 테이블은 어디에도 실제로 저장되지 않는다는 점을 강조하기 위해 이를 ‘가상 테이블’이라고 부르겠다. 데이터베이스는 데이터베이스에 대한 쿼리에 답할 필요가 있을 때마다 이를 만들고 즉시 삭제한다.
그림 8-4의 데이터베이스에서 커비 교수의 강의를 수강하는 모든 학생의 이름을 요청하는 쿼리를 입력한다고 하자. 실제로 데이터베이스는 다양한 방법으로 이 쿼리를 실행할 수 있다. 우리는 이 중 하나만 검토하겠다. 첫 단계는 모든 강의의 학생과 강사를 나열한 새로운 가상 테이블의 제작이다. 두 테이블의 조인(join)이라는 데이터베이스 연산을 이용하면 가능하다. 조인 연산의 기본 아이디어는 두 테이블에 모두 있는 키를 이용해 한 테이블의 각 행을 다른 테이블에서 대응하는 행과 결합하는 것이다.
데이터베이스는 두 테이블을 결합하는 조인 연산 후엔 불필요한 열을 제거하는 추출 연산을 하고 가상 테이블을 산출한다.

데이터베이스는 셀렉트(select)라는 또 하나의 중요한 연산을 이용한다. 셀렉트 연산은 특정 기준을 기반으로 테이블에서 일부 열을 선택하고 나머지 행을 버려 새로운 가상 테이블을 만든다. 이 예에서 우리는 커비 교수의 강의를 듣는 학생을 찾고 있으므로 강사가 ‘커비’인행만을 고르는 ‘셀렉트’ 연산을 실행해야 한다.

이젠 프로젝션 연산을 한 번 더 해서 ‘강사’열을 버리면 원래 쿼리에 답하는 가상 테이블이 나온다.

관계형 데이터베이스
상호 연결된 테이블에 있는 모든 데이터를 저장하는 데이터베이스를 관계형 데이터베이스라 부른다.
관계형 데이터베이스를 쓰면 효율적으로 조직된 테이블에 데이터를 저장할 수 있으며, 가상 테이블 트릭을 써서 서로 다른 양식으로 존재하는 데이터를 필요로 하는 듯한 쿼리에 답할 수 있다.
관계형 데이터베이스는 상당수의 전자상거래에 이용된다. 사람들은 온라인에서 물건을 살 때마다 제품과 고객, 개인 구입에 관한 정보를 저장하는 많은 관계형 데이터베이스 테이블과 데이터를 주고받는다. 사이버 공간에서 우리가 인식하진 못하지만 늘 관계형 데이터베이스에 둘러 싸여 있는 셈이다.
데이터베이스의 인간적 측면
‘장애 허용(fault tolerance)’ :: 구성 부품의 일부가 고장나도 정상적으로 처리를 수행하는 시스템
9. 디지털 서명: 진짜 누가 이 소프트웨어를 작성했을까?
이 책에서 접하는 모든 알고리즘 중 ‘디지털 서명’이라는 개념이 가장 역설적이다. ‘디지털(digital)’이라는 단어를 문자 그대로 해석하면 ‘숫자 열로 구성된’이란 뜻이다. 그러므로 정의상 디지털인 모든 대상을 복사할 수 있다. 숫자를 한 번에 하나씩 복사하기만 하면 된다. 읽을 수 있다면 복사할 수 있다! 반면 ‘서명(signature)’의 핵심은 서명한 사람 이외의 사람이 읽을 순 있지만 복사(위조)할 수 없다는 데 있다.
디지털 서명의 실제 목적은?

종이 서명에서는 여러분이 상대방에게 보낼 내용에 서명을 하지만, 디지털 서명에서는 상대방이 여러분에게 내용을 보내기 전에 서명을 한다. 사람들이 잘 인식하지 못하는 이유는 컴퓨터가 디지털서명을 자동으로 확인하기 때문이다. 예를 들어 프로그램을 다운로드해서 실행하려 할 때마다 웹브라우저는 프로그램이 디지털 서명을 갖고 있는지 그리고 이 서명이 유효한지 확인한다. 그리고 컴퓨터는 그림 9-1과 같은 적절한 경고를 띄운다.
소프트웨어가 유효한 서명을 갖고 있으면 컴퓨터는 이 소프트웨어를 작성한 회사의 이름을 확실하게 말할 수 있다. 물론 그렇다고 해서 소프트웨어의 안전성이 보장되는 것은 아니지만, 적어도 사용자가 이 회사에 갖고 있는 신뢰 정도를 기반으로 결정을 할 수 있다. 반면 서명이 유효하지 않거나 없는 경우 소프트웨어가 실제로 어디서 작성됐는지 확신할 수 없다. 유명 회사의 소프트웨어를 다운로드한다고 생각할 때도 해커가 이를 악성 소프트웨어로 바꿨을 가능성도 있다. 또는 유효 디지털 서명을 제작할 시간이나 필요가 없는 아마추어가 제작한 소프트웨어일 수 있다. 이런 상황에서 소프트웨어를 신뢰할지 결정하는 일은 사용자에게 달려 있다.
주소가 ‘https’로 시작하는 안전한 서버는 일반적으로 암호화 세션을 착수하기 전에 디지털 서명을 한 인증서를 여러분의 컴퓨터로 보낸다. 브라우저 플러그인 같은 소프트웨어 요소의 진본성(authenticity)을 검증하는 데도 디지털 서명을 이용한다.
자물쇠로 서명하기
디지털 서명으로 가는 첫 단계는 종이 서명을 모두 폐기하고 문서를 인증하는 새로운 방법을 채택하는 것이다. 이는 자물쇠, 키key(열쇠), 금고다. 새로운 체계에 참여하는 모든 사람(여기서 라비, 타케시, 프랑수아즈)은 자물쇠를 많이 갖고 있다. 한 사람에게 속한 자물쇠는 동일해야 한다는 점이 중요하다. 그러므로 라비의 자물쇠는 모두 똑같다. 또 각 참여자의 자물쇠는 서로 배타적이어야 한다. 누구도 라비의 자물쇠와 같은 자물쇠를 만들거나 입수할 수 없다. 마지막으로 모든 자물쇠는 소유자만 자물쇠를 열 수 있게 하는 독특한 생체 인증 센서가 달려 있다. 따라서 프랑수아즈가 라비의 열린 자물쇠를 발견했다 해도 이를 다른 것을 잠그는 데 쓸 수 없다. 이를 ‘물리적 자물쇠 트릭’이라 하자.
라비는 “라비는 프랑수아즈에게 $100를 지급하기로 약속한다.”라고 적은 문서를 만들지만 여기에 서명하지 않는다. 그는 이 문서의 사본을 만들고 이 문서를 금고(자물쇠로 잠글 수 있는 튼튼하게 만든 상자)에 넣는다. 마지막으로 라비는 상자를 그의 자물쇠로 잠그고 금고를 프랑수아즈에게 준다. 금고는 문서에 대한 서명인 셈이다. 라비가 서명을 제작하는 동안 프랑수아즈나 다른 믿을 만한 증인이 보는 편이 좋다는 점에 주의하라. 그렇게 하지 않으면 라비는 다른 문서를 상자에 넣어 속일 수도 있다.(거의 틀림없이 금고가 투명할 경우 이 체계는 훨씬 좋은 효과를 낸다. 결국 디지털 서명은 비밀이 아닌 진본성을 제공한다.)

누군가 또는 라비 자신이 문서의 진본성을 부정하려 할 경우 프랑수아즈는 “좋아. 라비. 잠깐만 네 키 하나만 빌려줘. 지금 네 키로 이 금고를 열겠다.”라고 말할 수 있다. 라비와 다른 증인 앞에서 (또는 법원의 판사 앞에서) 프랑수아즈는 자물쇠를 열고 금고의 내용을 보여 준다. 그리고 프랑수아즈는 이렇게 말할 수 있다. “라비, 이 키만 작동하는 자물쇠를 열 수 있는 사람은 당신밖에 없으니 다른 사람에겐 이 금고의 내용에 대한 책임이 없다. 따라서 당신만이 이 문서를 작성해서 금고 안에 넣었다는 뜻이다. 당신은 내게 $100를 빚졌다.”
이 방법의 가장 큰 문제는 이 방법이 라비의 협력을 요한다는 점이다. 프랑수아즈는 어떤 것을 증명하기에 앞서 라비를 설득해 그의 키 하나를 빌려야 한다. 그러나 라비는 거절할 수도 있고, 협력하는 척하고는 그의 자물쇠를 열 수 없는 다른 키를 건네줄 수도 있다. 그렇게 되면 프랑수아즈가 금고를 열지 못할 때 라비는 “봐라. 이건 내 자물쇠가 아니다. 그러므로 나도 모르게 위조범이 문서를 만들어서 이 상자에 넣었을지도 모른다.”라고 말할지도 모른다.
라비의 이런 교활한 접근을 예방하고자 은행 같은 신뢰할 만한 제3자에 의존할 필요가 있다. 은행은 키를 보관한다. 그러므로 참여자들은 은행에 서명 사본을 주는 대신 자기 자물쇠를 여는 키를 맡긴다. 라비가 차용증을 썼다는 사실을 프랑수아즈가 증명할 필요가 있을 경우 증인과 함께 은행에 금고를 가져가 라비의 키를 열면 된다. 자물쇠가 열린다는 사실은 라비만이 상자의 내용에 책임이 있다는 뜻이고, 상자에는 프랑수아즈가 입증하려는 문서 사본이 들어 있다.
곱셈 자물쇠로 서명하기
이제 자물쇠와 키를 디지털 방식으로 해석할 수 있는 수학적 대상과 교체할 단계다. 수가 자물쇠와 키를 의미하고, 시계 연산에서의 곱셈이 잠금 및 잠금 해제를 의미한다.
위조가 불가능한 디지털 서명을 제작하기 위해 컴퓨터는 매우 큰 시계 크기를 이용한다. 그러나 이 설명에서 계산을 단순화하기 위해, 11크기의 시계를 이용하겠다.
물리적 자물쇠 트릭과 마찬가지로 라비는 자물쇠와 이를 열 키를 필요로 한다. 우선 시계 크기를 선택하고 이 시계 크기보다 작은 숫자를 그의 숫자 ‘자물쇠’로 고른다.

라비의 메시지의 ‘잠긴’ 버전은(당연히 시계 크기 11을 이용해) 메시지로 곱한 자물쇠가 된다. 그러므로 라비의 메시지를 ‘5’라고 하자. 그러면 그의 ‘잠긴’ 메시지는 6x5=8(시계 크기 11)이 된다. 최종 결과 ‘8’은 원본 메시지에 대한 라비의 디지털 서명이다.

자물쇠로 잠긴 메시지는 키를 곱해서 연다. 라비는 메시지 5를 자물쇠 6으로 잠글 때 8이라는 잠긴 메시지(디지털 서명)를 얻었다(5x6%11=8). 이를 열고자 8에 키 2를 곱한다. 이 값에 시계크기를 적용하면 5가 된다(8x2%11=5).
서명을 받아 서명자의 곱셈 키를 이용해 풀면 된다. 결과 메시지가 원본 메시지와 일치하면 이 서명은 진짜다. 그렇지 않으면 이는 위조된 서명이다.
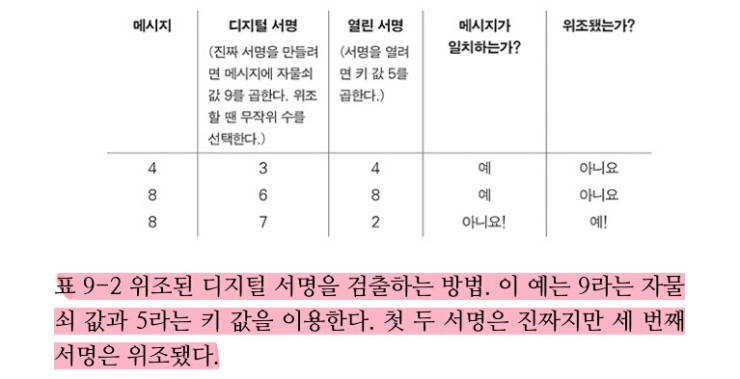
라비는 그의 자물쇠 번호를 비밀로 간직해야 한다. 메시지에 서명할 때마다 메시지와 서명을 노출할 수 있지만 서명을 제작하는 데 이용한 자물쇠 숫자를 노출할 수는 없다.
라비의 시계 크기와 숫자 키는 이것도 비밀로 간직해야 할까? 아니다. 라비는 서명 검증 체계를 위태롭게 하지 않고도 그의 시계 크기와 키 값을 웹사이트에 발행해 대중에게 발표할 수 있다. 라비가 그의 시계 크기와 키 값을 발행하면 누구나 이 숫자를 입수해 그의 서명을 검증할 수 있다.
은행같은 신뢰할 만한 제3자가 여전히 필요하다. 이것이 없으면 라비는 그의 서명을 유효하지 않게 만들 잘못된 키를 배포할 수도 있다. 심지어 라비의 적이 새로운 숫자 자물쇠와 이에 대응하는 숫자 키를 제작하고 이것이 라비의 키라고 발표하는 웹사이트를 만들어 최근 생성된 숫자 자물쇠를 이용해 원하는 어떤 메시지에도 디지털 서명을 할 수도 있다. 은행의 역할은 라비의 키와 시계 크기를 비밀로 유지하는 것이 아니다. 대신 은행은 라비의 숫자 키와 자물쇠 크기의 값에 대한 믿을 만한 기관이다.

숫자 자물쇠는 ‘비공개적(private)’인 반면 숫자 키와 시계 크기는 ‘공개적(public)’이다.
한 자리 숫자보다 긴 메시지에 서명하려면 어떻게 해야 할까? 이 질문엔 다양한 답이 가능하다. 가장 손쉬운 해결책은 훨씬 큰 시계 크기를 이용하는 것이다. 예컨대 100자리 시계 크기를 이용하면 똑같은 방법을 이용해 100자리 서명을 이용해 100자리 메시지에 서명할 수 있다. 이보다 긴 메시지에선 이를 100자리 청크로 나눠 각 청크에 별도로 서명할 수 있다. 그러나 컴퓨터과학자들은 이보다 더 좋은 방법을 갖고 있다. 암호학적 해시 함수라는 변환을 적용해 긴 메시지를 (예컨대 100자리 숫자로 이뤄진) 하나의 청크로 줄인다. 긴 메시지에 서명하기 전에 이를 훨씬 작은 청크로 줄인다. 이는 소프트웨어 패키지처럼 극도로 큰 ‘메시지’에 효율적으로 서명할 수 있다는 뜻이다. 참여자들은 기본적으로 자기 자물쇠로 어떤 숫자든 선택할 수 있다. 시계크기가 소수(素數)라면 시계 크기보다 작은 모든 양의 값은 자물쇠로 작동한다. 그렇지 않으면 상황이 더 복잡해진다. 소수는 1과 자신 외에 약수가 없는 수다. 그러므로 이 장에서 지금까지 쓴 시계 크기인 11이 소수임을 알 수 있다.
그리고 자물쇠를 선택하고 나서도 이 자물쇠를 열 숫자 키를 떠올려야 한다. 핵심 아이디어는 그리스 수학자 유클리드가 2000년도 더 전에 작성한 ‘유클리드 알고리즘’이라는 기법이다. 자물쇠 값이 주어지면 컴퓨터가 유클리드 알고리즘이라는 유명한 수학 기법을 이용해 이에 대응하는 키 값을 떠올릴 수 있다.
유클리드 알고리즘 :: 유클리드 호제법(- 互除法, Euclidean algorithm)은 2개의 자연수 또는 정식(整式)의 최대공약수를 구하는 알고리즘의 하나이다. 호제법이란 말은 두 수가 서로(互) 상대방 수를 나누어(除)서 결국 원하는 수를 얻는 알고리즘을 나타낸다. 2개의 자연수(또는 정식) a, b에 대해서 a를 b로 나눈 나머지를 r이라 하면(단, a>b), a와 b의 최대공약수는 b와 r의 최대공약수와 같다. 이 성질에 따라, b를 r로 나눈 나머지 r'를 구하고, 다시 r을 r'로 나눈 나머지를 구하는 과정을 반복하여 나머지가 0이 되었을 때 나누는 수가 a와 b의 최대공약수이다. 이는 명시적으로 기술된 가장 오래된 알고리즘으로서도 알려져 있으며, 기원전 300년경에 쓰인 유클리드의 《원론》 제7권, 명제 1부터 3까지에 해당한다.
[위키백과] 유클리드 호제법
곱셈 접근에 있는 결함을 살펴보자. 자물쇠 값이 비공개적(즉 비밀)인 반면 키 값은 공개적이라는 사실을 상기하라. 방금 이야기했듯 서명 체계의 참여자는 (공개적인) 시계 크기와 (비공개적인) 자물쇠 값을 자유롭게 고르고 컴퓨터를 이용해 (지금까지 본 곱셈 키 사례에서 유클리드 알고리즘을 통해) 자물쇠에 대응하는 키 값을 생성한다. 키를 신뢰할 만한 은행에 저장하고 은행은 키를 요청하는 누구에게나 공개한다. 키 곱하기의 문제는 같은 자물쇠로부터 키를 생성하는데 이용한 트릭(기본적으로 유클리드 알고리즘)이 역으로도 완벽히 작동한다는 점이다. 즉 컴퓨터는 똑같은 기법을 이용해 주어진 키 값에 대응하는 자물쇠 값을 생성할 수 있다! 이 기법이 디지털 서명 체계 전체를 뒤흔드는 이유를 즉시 알 수 있다. 키 값은 공개적이기 때문에 누구나 비밀이어야 할 자물쇠 값을 계산할 수 있다. 그리고 다른 사람이 자물쇠 값을 알게 되면 이 사람의 디지털 서명을 위조할 수 있다.
지수 자물쇠로 서명하기
34 같은 표현에서 4를 지수또는 제곱이라고 부르고 3을 기저수라 부른다. 지수를 기저수에 적용하는 과정은 거듭제곱 또는 (더 공식적으로) 누승법이라 부른다.
진짜 디지털 서명은 앞선 절에서 다룬 곱셈 방법과 똑같이 작동한다. 다만 이번에는 곱셈을 이용해 메시지를 잠그고 여는 대신, 누승법을 쓴다. 전과 마찬가지로 라비는 우선 공개할 시계 크기를 고른다. 여기서 라비는 시계 크기 22를 쓴다. 그러고 나서 그는 이 시계 크기보다 작은 숫자 중 비밀 자물쇠 값을 선택한다. 이 예에서 라비는 3을 자물쇠 값으로 고른다. 그리고 그는 컴퓨터를 이용해 이 자물쇠 값과 시계 크기에 대응하는 키 값을 계산한다. 컴퓨터는 유명한 수학기법을 이용해 자물괴와 시계 크기로부터 키를 쉽게 계산 할 수 있다. 이 경우 앞서 선택환 자물쇠 값 3에 대응하는 키 값은 7이다.

메시지가 ‘4’라면 서명은 ‘20’이다. 자물쇠를 지수로 이용해 메시지를 거듭제곱해 이를 구한다. 따라서 우리는 43을 계산해야 하고 이는 시계 크기를 고려하면 20이 된다. 프랑수아즈는 라비의 디지털 서명 ‘20’을 검증하고 싶을 경우 우선 은행에 가서 라비의 시계 크기와 키에 해당하는 인증된 값을 얻는다. 그러면 프랑수아즈는 서명에 키 값만큼 거듭제곱하고 시계 크기를 적용한다. 207 = 4가 된다. 결과가 원본 메시지와 일치하면 (그리고 이 경우 두 값이 일치하므로) 서명은 진본이다.

지수 자물쇠 및 지수 키 체계는 1970년대에 이 시스템을 처음 발표한 고안자의 이름(로날드 라이베스트, 아디 샤미르, 레너드 에이들먼)을 따라 RSA 디지털 서명 체계로 알려져 있다. 이 이름들이 왠지 익숙하게 들릴 수도 있다. RSA는 공개 키 암호화 체계인 동시에 디지털 서명 체계다.
RSA 시스템에서 시계 크기, 자물쇠, 키를 선택하는 상세한 방법은 정말 매력적이지만 이 접근 전반을 이해하는 데 필요하진 않다. 가장 중요한 점은, 이 시스템에서 참여자가 자물쇠 값을 선택하면 적합한 키 값을 쉽게 계산할 수 있다는 사실이다. 그러나 다른 사람이 이 과정을 거꾸로 실행하기는 불가능하다. 다른 사람이 이용하는 키와 시계 크기를 안다고 해서 이에 대응하는 자물쇠 값을 계산할 수는 없다. 이는 앞서 설명한 곱셈 시스템에 있는 결점을 수정한다.
RSA의 보안
모든 디지털 서명 체계의 보안 문제는 ‘적이 내 서명을 위조할 수 있는가?’란 질문으로 압축된다. 따라서 RSA에서 이는 ‘적이 공개 시계 크기와 키 값을 이용해 비공개 자물쇠 값을 계산할 수 있는가?’라는 질문이 된다.
사실 우리는 시행착오를 거쳐 누군가의 자물쇠값을 계산해 내는 일이 늘 가능하다는 사실을 알고 있다. 결국 우리는 메시지와 시계 크기, 디지털 서명을 받는다. 자물쇠 값이 시계 크기보다 작다는 사실을 알고 있으므로 모든 가능한 자물쇠 값을 차례로 시도해보고 정확한 서명을 산출한 값을 알아낼 수 있다. 이는 메시지를 가능한 각 자물쇠 값의 크기만큼 거듭제곱해보면 되는 일이다. 문제는 실제로 RSA 체계는 엄청나게 큰 시계 크기를 쓴다는 데 있다. 현존하는 슈퍼 컴퓨터 중 가장 빠른 컴퓨터조차 모든 가능한 자물쇠 값을 시도해 보는 데 수조 년이 걸린다.
RSA와 인수분해의 관계
서명자가 RSA 시계 크기를 생성하는 방법을 탐구할 준비가 됐다. 라비가 첫 번째로 할 일은 매우 큰 소수 두 개를 선택하는 것이다. 일반적으로는 수백 자리 수지만 여기선 라비가 2와 11을 그의 소수로 골랐다고 하자. 그 다음에 라비는 이를 곱해서 시계 크기를 만든다. 따라서 여기서 시계 크기는 2×11 = 22가 된다. 시계 크기는 라비의 키 값과 함께 공개된다. 그러나 이 시계 크기의 두 소인수는 비밀로 남아 있어 라비만 알 수 있다. RSA 이면의 수학은 라비에게 이 두 소인수를 이용해 키 값으로부터 자물쇠 값을 계산하고, 역으로 자물쇠 값으로부터 키 값을 계산할 방법을 제공한다.
해커도 시계 크기의 두 소인수를 안다면 비밀 자물쇠 값을 쉽게 계산할 수 있다. 다시 말해 라비의 적이 시계 크기를 인수분해할 수 있다면, 그의 서명을 위조할 수도 있다(물론 RSA를 크랙(crack)하는 다른 방법도 있다. 시계 크기의 효율적 인수분해는 가능한 공격 방법의 하나일 뿐이다).
시계 크기가 수백 또는 수천 자리 길이일 경우 인수 찾기란 극도로 어려운 문제가 된다. 사실 인류는 ‘소인수분해’ 문제를 수백 년 동안 연구해왔지만 전형적인 RSA 시계 크기를 위협할 정도로 효율적으로 작용하는 보편적인 풀이법을 찾지는 못했다.
라비는 두 소수(2와 11)을 선택하고 이 둘을 곱해 시계 크기(22)를 만든다. 이를 곧 알게 될 이유에서 ‘주’ 시계 크기라 부르자. 그리고 라비는 원래 소수에서 1씩 빼 만든 두 수를 곱한다. 이는 라비의 ‘보조’ 시계 크기를 만든다. 이 예에서 두 소수에서 1씩 빼면 라비는 1과 10을 얻게 되므로 보조 시계 크기는 1×10=10이 된다.
여기서 앞서 설명한 결함이 있는 자물쇠와 키 곱셈 시스템과의 매우 만족스러운 연결을 접한다. 라비는 곱셈 체계에 따라 자물쇠와 키를 선택하지만 주 시계크기 대신 보조 시계 크기를 이용해서 이를 구한다. 라비가 3을 자물쇠 수로 선택한다고 하자. 보조 시계 크기 10을 이용하면 대응하는 곱셈 키는 7이 된다. 이것이 작동하는지 빨리 검증할 수 있다. 메시지 ‘8’을 자물쇠 3과 곱하면 8×3=24 또는 시계 크기 10에서 ‘4’가 된다. 키로 ‘4’를 열면 4×7=28이므로 시계 크기를 적용하면 ‘8’이 된다. 이는 원본 메시지와 같다.
라비의 작업은 다 끝났다. 그는 방금 고른 곱셈 자물쇠와 키를 취해 RSA 시스템에서 그의 지수 자물쇠와 키로 바로 이용한다. 물론 주 시계 크기인 22를 이용한다.
수학자 페르마와 메르센이 17세기에 소인수 분해를 최초로 진지하게 탐구했다. (수학에서 가장 위대한 인물 중 두 명인) 오일러와 가우스는 18세기에 큰 기여를 했고 많은 다른 수학자가 이를 기반으로 문제를 탐구해 왔다. 그러나 1970년대에 공개 키 암호화를 발견하고 나서야 큰 수를 인수분해하기가 매우 어렵다는 것이 실제 응용에서 핵심이 됐다. 여러분도 알다시피 큰 수를 인수분해하는 효율적 알고리즘을 발견한다면 누구나 디지털 서명을 마음대로 위조할 수 있을 것이다.
어떤 체계도 안전하다고 ‘증명된’ 것은 없다. 이들은 분명히 매우 어렵고 많이 연구된 수학 문제에 의존하고 있지만 어느 문제에서도 이론적으로 효율적 해결책이 존재하지 않는다는 사실을 증명하지 못했다. 그러므로 전문가는 일어날 가능성이 거의 없다고 생각하더라도, 원리상 언제라도 이런 암호화나 디지털 서명 체계는 무너질 수 있다.
RSA와 양자 컴퓨터의 관계
고전 물리학의 결정론적 법칙과 달리 양자 역학에서 대상의 움직임은 확률이 지배한다. 따라서 양자 역학의 효과에 반응하도록 컴퓨터를 구축할 경우, 컴퓨터가 계산하는 값은 일반적인 컴퓨터가 생산하는 0과 1의 절대적인 배열이 아니며, 확률에 따라 결정된다. 이를 보는 또 다른 방법은 양자 컴퓨터가 다양한 값을 동시에 저장한다는 사실이다. 모든 값은 각기 다른 확률을 갖지만, 컴퓨터에게 강요해 최종 답을 산출하게 할 때까지 이 다양한 값은 동시에 존재한다. 이는 양자 컴퓨터가 서로 다른 가능한 답을 동시에 계산할 가능성을 초래한다. 그러므로 특수한 유형의 문제에 대해서 모든 가능한 해결책을 동시에 시도하는 ‘브루트 포스’를 이용할 수 있다!
일반 컴퓨터가 아닌 양자 컴퓨터에서 소인수분해를 훨씬 더 효율적으로 수행할 수 있다. 그러므로 수천 자리 숫자를 처리할 수 있는 양자 컴퓨터를 만들 수 있다면 앞서 설명한 RSA 서명을 위조할 수도 있다.
이 글을 쓰고 있는 2011년에 양자 컴퓨팅 이론은 실제 양자 컴퓨터보다 훨씬 앞서 있다. 연구자들은 실제 양자 컴퓨터를 만들 수는 있지만, 이 양자 컴퓨터가 지금까지 계산한 가장 큰 인수 분해는 15=3x5다. 2012년에는 21의 인수분해도 수행했다.
실제 디지털 서명
모든 체계는 공개 키와 시계 크기를 저장할 일종의 신뢰할 만한 ‘은행’을 요한다. 실제로 공개키를 저장하는 신뢰할 만한 조직은 인증기관(certification authority)으로 알려져 있다. 모든 인증기관은 전자 접속으로 공개 키 정보를 다운로드할 수 있는 서버를 운영한다. 그래서 사용자의 컴퓨터가 디지털 서명을 받으면 이는 어떤 인증기관이 서명자의 공개 키를 보증하는지 언급하는 정보를 수반한다.
컴퓨터는 지정된 인증기관을 이용해 서명을 검증할 수 있지만, 인증기관을 어떻게 신뢰할 수 있을까? 이 연쇄의 끝에 있는 조직을 어떻게 믿을 수 있을까? 특정 조직을 최상위(root) 인증기관으로 공식 지정하면 된다. 잘 알려진 최상위 인증기관으로는 베리사인(VeriSign), 글로벌사인(GlobalSign), 지오트러스트(GeoTrust)가 있다. 수많은 최상위 인증기관의 (인터넷 주소와 공개 키를 포함한) 연락 정보는 브라우저에 사전 설치되고, 이것이 디지털 서명에 대한 신뢰 연쇄가 신뢰할 만한 출발점에 닻을 내리게 되는 방식이다.
해결된 역설
서명은 다른 메시지로 전환될 수 없으므로, 이를 그냥 복사한다고 해서 위조할 수 있는 것은 아니다.
10. 계산 가능성과 결정 불가능성: 컴퓨터로 모든 문제를 해결할 수 있을까?
1930년대 말 미국인 수학자와 영국인 수학자는 컴퓨터로 해결할 수 없는 문제가 있다는 사실을 각자 밝혀냈다. 미국인 수학자는 컴퓨터과학의 많은 분야에서 이론적 기초를 세운 계산 이론(theory of computation)을 정립한 알론조 처치였고, 영국인 수학자는 바로 컴퓨터과학 창립에 가장 중요한 역할을 한 앨런 튜링이었다.
앨런 튜링 :: 1912년 6월 23일 영국에서 태어난 튜링은 케임브리지 킹스 칼리지에서 수학을 전공했으며, 24살에 현대 컴퓨터의 전신이라 할 수 있는 '보편 튜링기계'에 대한 이론체계를 만들어 냈다. 2차 세계 대전 중에는 '폭탄(bombe)'이라는 암호해독기를 만들어 독일군의 암호체계인 '에니그마'를 해독했는데, 이 암호해독기 시스템이 바로 현대 컴퓨터 과학의 시초가 되었다.
하지만 동성애자였던 튜링은 당시 동성애를 범죄로 취급했던 영국 정부에 의해 화학적 거세를 당했으며 여성 호르몬까지 주입받는 수모를 겪었다. 수치심과 외로움을 견디지 못한 튜링은 1954년 6월 7일 42세의 나이에 자살하였다. 청산가리를 주입한 사과를 베어물고 자살한 이 사건은 애플사의 한 입 베어 먹은 사과 로고가 그를 기리기 위해 만든 것이라는 추측이 나오기도 하였다. 영국 정부는 2009년에 와서야 '그에 대한 정부의 처사는 부당하였으며 깊은 유감의 뜻을 표한다.'는 공식 성명을 발표하였다. 한편 계산기학회에서 컴퓨터 과학에 중요한 업적을 남긴 사람들에게 매년 수상하는 튜링상은 그의 이름을 딴 것이다.
[네이버 지식백과] 앨런 튜링 [Alan Mathison Turing] (시사상식사전, 박문각)
버그, 충돌, 소프트웨어의 신뢰성
자동 소프트웨어 검사 도구는 모든 컴퓨터 프로그램에 있는 잠정적 문제를 모두 검출할 수 있는 수준에 도달하게 될까? 이런 ‘소프트웨어 해탈의 경지’에 절대 이를 수 없다. 어떠한 소프트웨어 검사 도구라도 ‘모든’ 프로그램에 잠재해 있는 충돌을 ‘모두’ 검출하는 일은 불가능하다는 것을 증명할 수 있다.
자연과학과는 아주 대조적으로, 수학과 컴퓨터과학에선 일부 결과가 100% 확실하다고 주장하는 일이 가능하다. (1+1=2 같은) 수학의 기본 원리를 수용한다면 수학자가 이용하는 연역 논증의 연쇄는 (예컨대 ‘5로 끝나는 모든 숫자는 5로 나눌 수 있다.’ 같은) 여러 가지 진술이 참이라는 사실을 절대적 확실성을 갖고 증명할 수 있다.
그러므로 컴퓨터과학에서 ‘X의 불가능은 증명 가능하다.’라고 말할 때 X가 매우 어려워 보인다거나 실제로 이를 달성하기란 불가능하다는 뜻이 아니다. 이는 X를 절대 달성할 수 없다는 사실이 100% 확실하다는 뜻이다.
어떤 명제가 참이 아님을 증명하기
귀류법(proof by contradiction) :: 어떤 명제(命題)가 진리임을 증명하려고 할 때, 주어진 전제(前提)에서 직접 증명하지 않고 그것의 부정명제를 전제에 포함시켜 논증이 모순에 귀결하는 것을 밝히는 간접적 증명의 방식. 주어진 명제 p가 진리임을 증명하기 위하여 그것의 부정명제인 ∼p를 전제군(前提群)에 포함시켜서 논리적 모순을 도출하면, 결국 p가 진리일 수밖에 없다는 증명이 되는 셈이다.
[네이버 지식백과] 귀류법 [歸謬法] (교육학용어사전, 1995.6.29., 하우동설)
추상적인 용어를 이용해 귀류법을 요약하겠다. 진술 S가 거짓이라는 의심을 하고 이것이 의심의 여지없이 거짓임을 증명하고 싶어한다고 하자. 첫째, S가 참이라고 가정한다. 이로부터 논증을 해 예컨대 T라는 다른 진술도 참이어야 한다는 결론에 이른다. 그러나 T가 거짓임이 알려져 있다면 모순에 도달한 셈이다. 이는 원래 가정 S가 거짓이어야 한다는 사실을 증명한다.
수학자는 이를 “S는 T를 내포하지만 T는 거짓이므로 S도 거짓이다.”라고 훨씬 간략히 진술한다.
다른 프로그램을 분석하는 프로그램
컴퓨터 프로그램이 매번 똑같은 결과를 산출한다는 사실은 참이지만, 우리가 매일 이용하는 프로그램 대부분은 실행할 때마다 매우 달라 보인다. 워드프로세서 프로그램을 생각해 보라. 시작할 때마다 늘 같은 화면이 나오는가? 당연히 아니다. 이는 사용자가 여는 문서에 따라 다르다.
한 가지 사실을 분명히 하자. 나는 마이크로소프트 워드라는 동일한 프로그램을 실행했다. 각 사례에서 다른 점은 입력(input)뿐이다. 모든 운영체제에서 마우스 더블클릭만으로 프로그램을 실행할 수 있다고 생각하지는 않길 바란다. 이는 친절한 컴퓨터 회사(거의 확실히 애플이나 마이크로소프트)가 제공해온 편의일 뿐이다.
메뉴를 클릭하거나 프로그램에 입력하는 행위는 프로그램에 추가적 입력을 주는 일이다. 그리고 파일을 저장하면 프로그램은 추가적 출력을 생산한다. 운영체제는 사용자가 파일을 더블 클릭할 때마다 어떤 프로그램을 실행해야 하는지 다양한 기발한 트릭을 서서 추측한다. 그러나 때로는 어떤 프로그램이라도 모든 종류의 파일을 열 수 있다는 사실, 달리 말하면, 어떤 파일이라도 모든 프로그램에서 실행될 수 있다는 사실을 알 필요가 있다. 모든 운영체제나 모든 입력 파일에서 작동하지는 않는다. 각 운영체제는 각기 다른 방식으로 프로그램을 실행하며, 때로는 보안 문제 때문에 입력 파일의 선택에 제한을 두기 때문이다.

어떤 파일을, 이를 실행하기로 고안되지 않은 프로그램으로 열면 분명히 예상치 못한 결과를 얻을 것이다. 내가 ‘photo.jpg’라는 그림 파일을 스프레드시트 프로그램인 마이크로소프트 엑셀로 열었을 경우 일어난 일을 볼 수 있다. 이 경우 출력은 쓰레기고 누구에게도 쓸모가 없다. 그러나 스프레드시트 프로그램은 실행됐고 결과물을 산출했다.
컴퓨터 프로그램도 컴퓨터의 디스크에 파일로 저장되어 있다는 사실을 기억하라. 대개 이런 프로그램은 ‘실행 가능한(executable)’이란 단어의 줄임말인 ‘.exe’로 끝나는 이름을 가진다. 이는 사용자가 프로그램을 ‘실행할’ 수 있다는 뜻이다. 따라서 컴퓨터 프로그램 또한 디스크에 있는 파일이기 때문에 하나의 컴퓨터 프로그램을 다른 컴퓨터 프로그램의 입력으로 이용할 수 있다. 마이크로소프트 워드는 ‘WINWORD.EXE’라는 파일로 내컴퓨터에 저장돼 있다. 따라서 WINWORD.EXE라는 파일을 입력으로 이용해 스프레드시트 프로그램을 실행해 환상적인 쓰레기를 산출할 수 있다.
컴퓨터 프로그램을 같은 컴퓨터 프로그램으로 실행하면 어떻게 될까? 예를 들어 WINWORD.EXE파일을 입력으로 이용해 마이크로소프트 워드를 실행하면 어떻게 될까? 앞선 예에서처럼 프로그램은 잘 실행되지만 화면에 뜬 출력은 거의 쓰레기다.
이쯤이면 나중에 매우 중요해질 다소 이상한 세 가지 개념에 익숙해져야 한다. 첫째, 어떤 파일이나 입력을 이용해서 어떤 프로그램이라도 실행할 수 있다는 개념이 있다. 그러나 입력 파일이 이를 실행한 프로그램의 목적에 맞는 파일이 아닌 경우, 결과 출력은 주로 쓰레기다. 둘째, 컴퓨터 프로그램도 컴퓨터 디스크에 파일로 저장되므로, 아무 프로그램이나 입력으로 이용해 어떤 프로그램이라도 실행할 수 있다는 사실을 알았다. 셋째, 한 컴퓨터 프로그램은 자기 자신을 입력으로 이용해 실행할 수 있다.
존재할 수 없는 프로그램
컴퓨터는 단순한 지시를 수행하는 일을 아주 잘한다. 사실 오늘날 컴퓨터는 단순한 지시를 매초 수십억 번씩 수행한다. 그러나 단순하고 정확한 영어지만 컴퓨터 프로그램으로 쓸 수 없는 진술이 있다.
단순한 예-아니요 프로그램
ProgramA.exe : 무조건 ‘예’ 출력
ProgramB.exe : 무조건 ‘아니요’ 출력
SizeChecker.exe : 입력된 파일의 크기가 10KB 넘으면 ‘예’, 그렇지 않을 경우 ‘아니요’ 출력
NameSize.exe : 입력된 파일 이름이 한 글자 이상이면 ‘예’, 그렇지 않을 경우 ‘아니요’ 출력
(정의상 모든 입력 파일의 이름은 한 글자 이상이다. 그러므로 NameSize.exe는 입력에 상관없이 늘 ‘예’를 출력한다.)

AlwaysYes.exe: 다른 프로그램을 분석하는 예-아니요 프로그램
AlwaysYes.exe : 입력 파일을 검토해서 이 파일이 늘 ‘예’를 출력하는 예-아니요 프로그램일 경우 ‘예’, 그렇지 않은 경우 ‘아니요’ 출력
(실행 가능한 프로그램이 아닌 경우, 실행 가능한 프로그램이지만 예-아니요 프로그램이 아닌 경우, ‘아니요’를 출력하는 예-아니요 프로그램일 경우 모두 ‘아니요’ 출력. 즉 ‘예’를 출력할 수 있는 유일한 방법은 입력에 상관없이 늘 ‘예’를 출력하는 예-아니요 프로그램을 입력하는 길 뿐 ex)ProgramA.exe, NameSize.exe)

Freeze.exe : 이 프로그램이 실행되면 (입력에 상관없이) 어떤 입력에도 응답을 거부한다.
YesOnSelf.exe: AlwaysYes.exe의 단순한 형태
YesOnSelf.exe : 자신을 입력으로 실행할 때 ‘예’를 출력하는 경우 ‘예’, 그렇지 않은 경우 ‘아니요’ 출력

YesOnSelf.exe 파일이 입력일 경우 YesOnSelf.exe는 무엇을 출력할까? 출력이 ‘예’인 경우 (YesOnSelf.exe의 정의에 따라) YesOnSelf.exe를 자신을 대상으로 실행할 경우 ‘예’를 출력해야 한다. 자신을 입력으로 YesOnSelf.exe를 실행할 때 출력이 ‘아니요’라면? (이번에도 YesOnSelf.exe의 정의에 따라) 이는 YesOnSelf.exe가 자신을 대상으로 실행될 때 ‘아니요’를 출력해야 한다는 뜻이다.
AntiYesOnSelf.exe: YesOnSelf.exed의 정반대
AntiYesOnSelf.exe : YesOnSelf.exe가 특정 입력에 ‘예’를 출력하는 경우 ‘아니요’, YesOnSelf.exe가 특정 입력에 ‘아니요’ 출력하는 경우 ‘예’ 출력
(입력 프로그램이 자신을 대상으로 실행될 때 ‘예’를 출력하지 않는다는 사실이 참인가?,
입력 프로그램이 자신을 대상으로 실행될 때 ‘아니요’를 출력하는가?)

AntiYesOnself.exe의 출력을 계산하려 할 때 문제가 생긴다. AntiYesOnself.exe가 자신을 대상으로 실행될 때 ‘아니요’를 출력하는가?
경우 1 (출력이 ‘예’인 경우): 출력이 ‘예’인 경우 질문에 대한 답은 ‘아니요’가 된다. 그러나 이 질문에 대한 답은 정의상 AntiYesOnself.exe의 출력이다. 그러므로 출력은 ‘아니요’가 돼야 한다. 이는 불가능하다! 우리는 모순에 도달했다. 모순을 발견했으므로 출력이 ‘예’라는 가정은 타당하지 않음에 틀림없다. AntiYesOnself.exe를 자신을 대상으로 실행할 때 출력은 ‘예’가 될 수 없음을 증명했다.
경우 2 (출력이 ‘아니요’인 경우): 출력이 ‘아니요’라면 질문에 대한 답은 ‘예’가 된다. 그러나 경우1에서처럼 이 질문에 대한 답은 정의상 AntiYesOnself.exe의 출력이다. 그러므로 출력은 ‘예’가 돼야 한다. 다시 말해 출력이 ‘아니요’라면 출력이 ‘예’라는 사실을 증명했다. 이번에도 모순에 도달했으므로 출력이 ‘아니요’라는 가정은 타당하지 않음에 틀림없다. AntiYesOnself.exe를 자신을 대상으로 실행할 때 출력은 ‘아니요’가 될 수 없음을 증명했다.
AntiYesOnself.exe를 자신을 대상으로 실행할 때 가능한 출력 두 개를 모두 제거했다. 이 역시 모순이다. AntiYesOnself.exe를 늘 종료되고 ‘예’ 또는 ‘아니요’ 중 하나만을 출력하는 프로그램으로 정의했기 때문이다. 이 모순은 우리의 첫 가정이 틀렸음을 내포한다. 그러므로 AntiYesOnself.exe처럼 작동하는 예-아니요 프로그램은 작성할 수 없다. 즉 AlwaysYes.exe와 YesOnSelf.exe도 존재할 수 없다! 이번에도 귀류법이 핵심도구다. AlwaysYes.exe가 존재한다면 이를 약간 변형해 YesOnSelf.exe를 제작하기란 매우 쉽다. 그리고 YesOnSelf.exe가 존재한다면 이 출력을 뒤집기만 하면 되는 AntiYesOnself.exe를 만들기란 매우 쉽다. 요약하자면 AlwaysYes.exe가 존재하면 AntiYesOnself.exe도 존재한다. 그러나 AntiYesOnself.exe가 존재할 수 없음을 이미 알고 있으므로 AlwaysYes.exe도 존재할 수 없다.
충돌 찾기의 불가능성
다른 프로그램을 분석해 충돌을 일으킬지 말해주는 CanCrash.exe라는 프로그램이 있다고 가정한다.
CanCrash.exe : 입력 프로그램이 어떤 상황에서 충돌할 수 있을 경우 ‘예’, 입력 프로그램이 절대 충돌을 일으키지 않으면 ‘아니요’를 출력

AntiCrashOnSelf.exe가 자신을 입력으로 이용하면 어떻게 될까? 정의에 따라 이 프로그램이 충돌하면 ‘예’를 출력해야 한다(이 프로그램이 이미 충돌했다면 ‘예’를 출력하며 성공적으로 종료될 수 없으므로 이는 모순이다). 또 정의에 따라 AntiCrashOnSelf.exe는 충돌하지 않으면 충돌해야 한다. 이 역시 자가당착이다.
변형의 연쇄를 이용해 CanCrash.exe도 존재할 수 없음을 증명할 수 있다. 이 프로그램이 존재한다면 이 그림의 화살표를 따라 변형해 AntiCrashOnSelf.exe를 만들 수 있다. 하지만 우리는 AntiCrashOnSelf.exe가 존재할 수 없음을 이미 알고 있다. 이는 모순이므로 CanCrash.exe가 존재한다는 가정은 거짓임에 틀림없다.
정지 문제와 결정 불가능성
프로그램을 분석해 충돌을 야기할지도 모르는 프로그램 내부의 모든 가능한 버그를 확인하는 CanCrash.exe 같은 프로그램을 누군가가 작성하는 일은 절대 불가능함을 증명했다.
“컴퓨터 프로그램은 계산을 끝내고 멈출 수 있을까? 아니면 멈추지 않고 영원히 계속해서 계산할 수 있을까?” 컴퓨터 프로그램이 결국 종료되는지, 즉 정지(halt)하는지에 관한 질문은 정지 문제(Halting Problem)라고 알려져 있다. 튜링의 위대한 업적은 컴퓨터과학자들이 ‘결정 불가능성’이라고 부르는, 다양하게 변형된 형태의 정지 문제를 증명해냈다는 것이다. 결정 불가능한 문제란, 컴퓨터 프로그램을 작성해서 해결할 수 없는 문제다. 따라서 튜링의 결론을 이렇게도 말할 수 있다. “입력이 늘 정지하면 ‘예’를 출력하고, 그렇지 않으면 ‘아니요’를 출력하는 AlwaysHalts.exe라는 컴퓨터 프로그램은 작성할 수 없다.”
우리는 충돌 문제의 결정 불가능성을 증명했고 기본적으로 같은 기법을 이용해 정지 문제도 결정 불가능함을 증명할 수 있다.
결정 불가능성과 컴퓨터 사용
결정 불가능성은 컴퓨터의 일상적 사용에 별다른 영향을 주지 않는다. 여기에 두 가지 이유가 있다. 첫째, 결정 불가능성은 컴퓨터 프로그램이 답을 산출할 수 있는지에만 관심이 있고 이 답을 하는 데 걸리는 시간은 고려하지 않는다. 그러나 실생활에서 효율성의 문제는 (즉 답을 기다리는 시간은) 극도로 중요하다.
외판원 문제(TSP, Traveling Salesman Problem) :: 본사가 있는 도시에서 출발하여 다른 도시들을 특정한 순서 없이 순회 방문하고 돌아오는 외판원이 당면하는 상황에서 그 명칭을 따온 것이다. 외판원은 같은 도시를 다시 방문하지 않고 최단 이동 시간으로 순회해야 한다. 외판원 문제는 말로는 쉽게 표현되지만 수학적으로는 표현하기가 까다롭다.
[네이버 지식백과] 여행하는 외판원 문제 [traveling salesman problem] (실험심리학용어사전, 2008, 시그마프레스㈜)
당신이 (20곳, 30곳, 100곳의) 수많은 도시를 비행기로 여행해야 한다고 하자. 가장 저렴한 항공료로 이용하려면 어떤 순서로 방문해야 할까? 이미 언급했듯 이 문제는 결정 가능하다. 사실 단 며칠만 일해본 초보 프로그래머도 가장 저렴한 여행 경로를 찾는 컴퓨터프로그램을 작성할 수 있다. 중요한 점은 이 프로그램이 작업을 완료하는 데 수백만 년의 시간이 걸린다는 사실이다. 이것은 현실적이지 않다. 그러므로 프로그램이 결정 가능하다고 해서 실제로 이를 해결할 수 있는 것은 아니다.
두 번째 이유를 보자. 모든 컴퓨터 프로그램에 있는 모든 버그를 찾을 수 있는 컴퓨터 프로그램은 없다는 사실을 보았다. 그럼에도 우리는 대부분 유형의 컴퓨터 프로그램에서 대부분의 버그를 찾아내는 충돌 검색 프로그램을 작성하기 위해 노력할 수 있다. 그러므로 결정 불가능한 문제에 매우 유용한 부분적 해결책을 만드는 일은 얼마든지 가능하다.
결정 불가능성과 인간의 뇌
이론상 컴퓨터로 인간의 뇌를 시뮬레이션할 수 있다면 뇌도 컴퓨터와 같은 한계에 부딪힌다. 다시 말해 (뇌가 똑똑하거나 훈련받은 정도에 상관없이) 인간의 뇌로 풀 수 없는 문제가 있을 것이다.
튜링은 컴퓨터과학에서 가장 근본적인 문제 일부를 정의하고 풀었을 뿐 아니라, (당시 실제로 만들어지지도 않은) 컴퓨터가 인간의 사고 과정을 모방(emulate)할 수도 있다는 설득력 있는 사례를 제시하며, 철학계에 도전장을 내밀었다. 모든 컴퓨터와 인간이 동등한 계산력을 가진다는 개념은 현대 철학 용어로 처치-튜링 명제로 알려져 있다.
처치-튜링 명제의 타당성에 관한 논의는 여전히 진행 중이다. 그러나 이 명제를 지지하는 가장 강력한 입장을 취하면 컴퓨터만이 결정 불가능성이란 한계에 부딪히는 것이 아니라고 말할 수 있다. 결정 불가능성의 한계는 우리 앞에 놓인 천재뿐 아니라 우리 안의 천재, 즉 정신에도 적용될 수 있다.
11. 마치면서: 미래의 알고리즘과 진화하는 컴퓨터
어떤 알고리즘은 응용 가능성이 넓은 새로운 테크놀로지를 기다리며 얼마 동안 연구진들 사이에서만 논의될 수도 있다. 검색엔진 인덱싱과 랭킹을 다루는 검색 알고리즘이 이 범주에 속한다. 이와 유사한 알고리즘이 이 분야에서 수년 전부터 정보 검색이라는 이름으로 존재했지만 일반 컴퓨터 사용자의 일상적 사용이라는 관점에서 웹 검색이라는 현상이 이런 알고리즘을 ‘위대하게’ 만들었다. 물론 알고리즘은 새로운 응용에 맞게 진화했다.
새로운 테크놀로지가 출현한다고 반드시 새로운 알고리즘이 생겨나는 것은 아님에 주의하라. 노트북 혁명이 그 어떤 위대한 알고리즘도 불러오지 않았다고 단언한다. 이와 달리 인터넷의 출현은 위대한 알고리즘을 낳았다.
컴퓨터과학은 1930년대에야 시작됐다. 그러므로 20세기에 발견된 위대한 알고리즘은 어쩌면 쉽게 얻은 열매들이고, 앞으로는 기발하고 널리 응용 가능한 알고리즘의 발견이 점점 더 어려워질 것이다.
최신 테크놀로지가 제공하는 새로운 틈새로 인해 새로운 알고리즘에 대한 시야가 넓어지지만, 이 분야가 성숙함에 따라 기회의 폭이 좁아진다. 이 둘을 모두 감안할 때 앞으로 이 두 효과가 서로 상쇄되면서 새로운 알고리즘은 천천히 그리고 꾸준히 출현할 것이다.
잠재력 있는 위대한 알고리즘 후보군
인공지능과 함께 비옥한 분야는 영지식 프로토콜(zero-knowledge protocol)이라는 알고리즘 부류다. 이 프로토콜은 특수한 유형의 암호화를 이용해 디지털 서명보다 훨씬 놀라운 것을 달성한다. 이는 두 개 이상의 개체가 단 하나의 정보도 노출하지 않고 정보를 결합할 수 있게 한다.
엄청난 양의 학문적 연구가 진행됐지만 실용적으로 그다지 쓰이지 않는 또 다른 알고리즘은 분산 해시 테이블(distributed hash table)이라는 기법이다. 이 테이블은 (정보의 흐름을 감독하는 중앙 서버가 없는) 피어투피어(P2P,peer-to-peer) 시스템에서 정보를 저장하는 기발한 방식이다. 그러나 이 글을 쓰고 있는 현재 P2P라고 주장하는 많은 시스템이 실은 기능성 때문에 중앙 서버를 이용하고 있어 분산 해시 테이블에 의존할 필요가 없다.
비잔틴 장애 허용(Byzantine fault tolerance)이라는 기법도 같은 범주에 속한다.
위대한 알고리즘도 사라질까?
MD5로 알려진 해시 함수는 공식 인터넷 표준이고 1990년대 초부터 널리 이용됐다. 그러나 MD5에서 심각한 보안의 문제를 발견했고 그 이후로 이 함수의 이용을 권하지 않는다.
MD5가 (그리고 이 함수의 주요 계승자인 SHA-1도) 깨진 것은 사실이지만 암호학적 해시 함수의 핵심 사고가 적합성을 잃었다는 뜻은 아니다. 실제로 이런 해시 함수는 매우 널리 이용되고 있고, 아직 크랙(crack)되지 않은 해시 함수가 많다. 그러므로 폭넓은 시야를 가지고 특정 알고리즘의 핵심 사고는 유지하되 세부적 내용을 변화에 적응시킬 준비가 되어 있다면, 현재 위대한 알고리즘 중 다수가 미래에 중요성을 잃게 될 가능성은 희박해 보인다.
이 책에서 얻은 교훈
컴퓨터과학의 분야는 프로그래밍을 훌쩍 넘어선다. 컴퓨터과학자에게 프로그래밍 언어에 관한 지식은 필수다. 그러나 이는 기본 요건에 불과하다. 가장 큰 도전은 알고리즘을 개발하고 적용하며 이해하는 것이다.
+. 감사의 글
내가 들어서서 주위를 돌아보는 길이여! 지금 내 눈에 보이는 모습이 당신의 전부가 아니라고 믿는다. 보이지 않는 많은 것도 여기에 있다고 믿는다.
- 월트 휘트먼, 《열린 길의 노래》



